
**Click here to get Record Data for R. Click here to get Record Data for Python. Click here to get Text Data.
1) SVM in R for Record Data: Click here to get R code.
| Scatterplot | Scatterplot Matrix |
|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
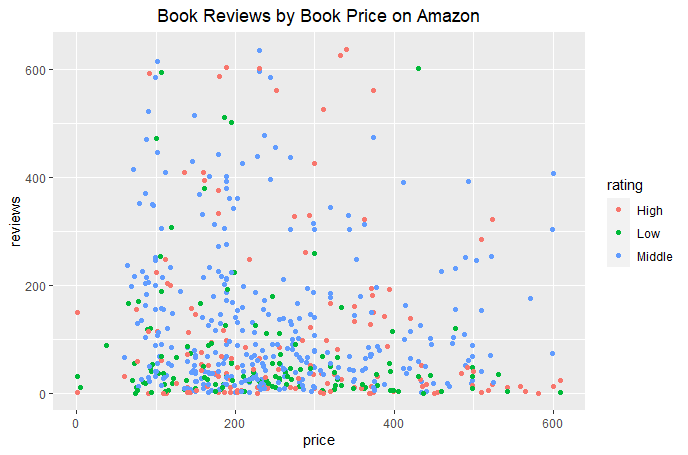
The labeled data is rating and it was divided into three classes: "High"-rating>4.5, "Middle"-4.5>=rating>4, "Low"-4>=rating.
| Classification Plot by Linear Kernel | Different Costs by Radial Kernel |
|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
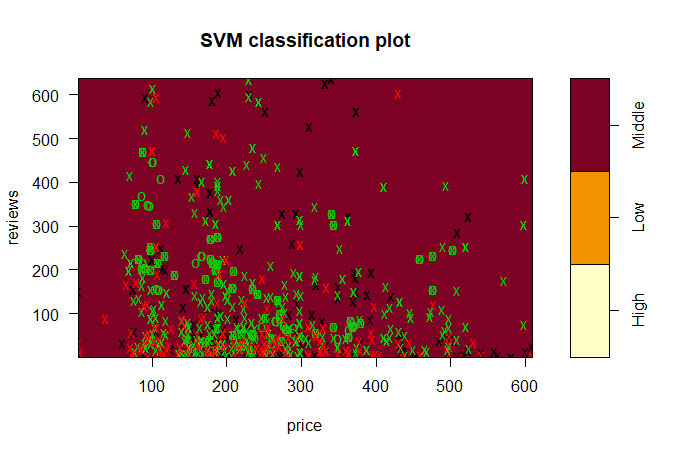
From the classification plot, all data are predicted as "Middle".
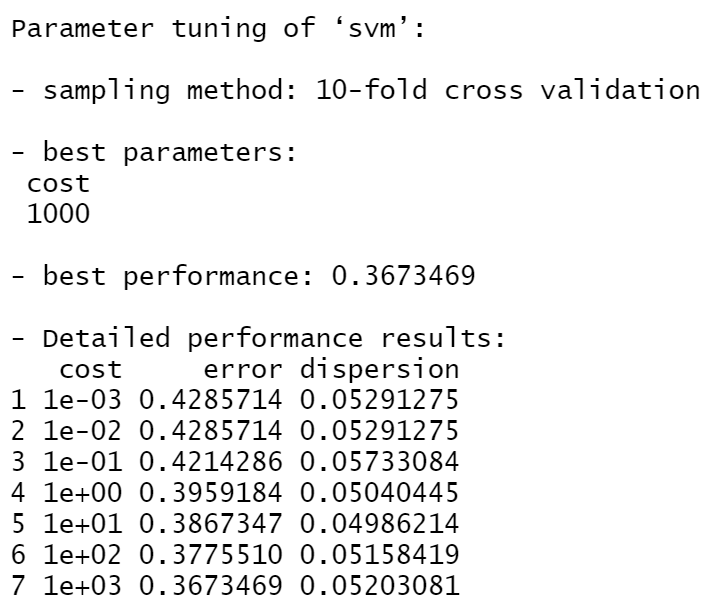
From the screenshot on the right, the best cost for model built by radial kernel is 1000, with the lowest error rate.
| Confusion Matrix | |
|---|---|
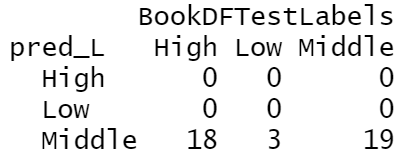
(Click to see a larger view.) |
All data are predicted as "Middle", which is the same as the classification plot. The accuracy of this model is 47.5%, and the misclassification rate is 52.5%. From the model built by linear kernel, 40 "Middle" are predicted and 19 are actually correct. |
2) SVM in R for Text Data: Click here to get R code.
| The First 10 Words Before Normalization |
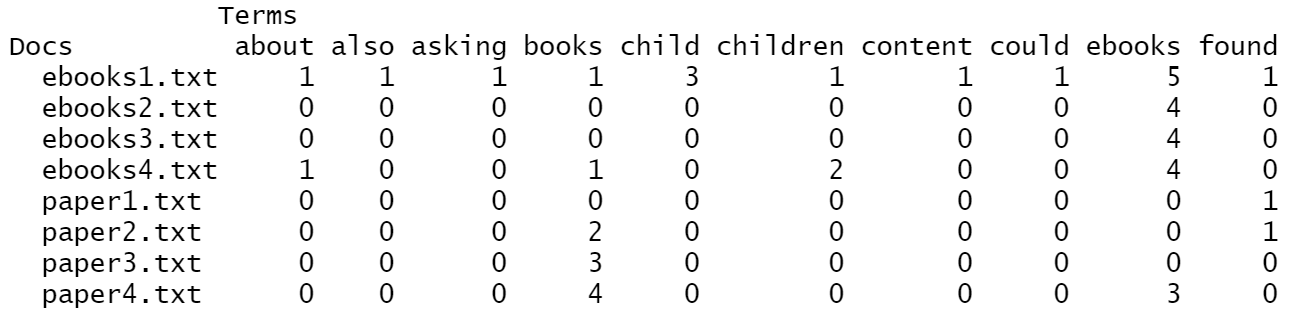
(Click to see a larger view.) |
| The First 10 Words After Normalization |
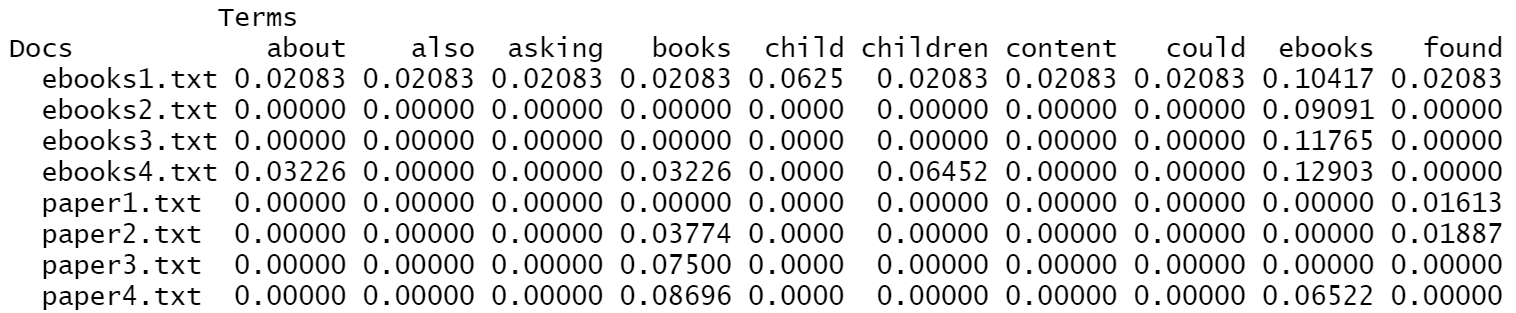
(Click to see a larger view.) |
Word "ebooks" occurs in every document labeled as "ebooks" and one of that labeled as "paper". Word "books" occurs in three of the documents labeled as "ebooks" and two of that labeled as "paper".
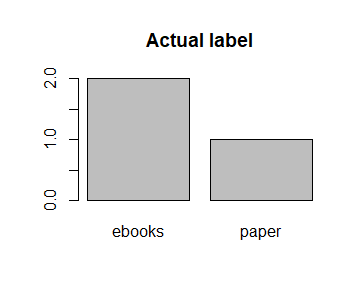
| Actual Label | Predicted Label by Linear Kernel | Predicted Label by Radial Kernel |
|---|---|---|
(Click to see a larger view.) |
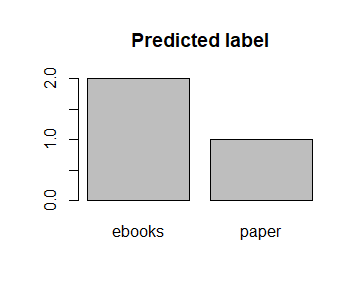
(Click to see a larger view.) |
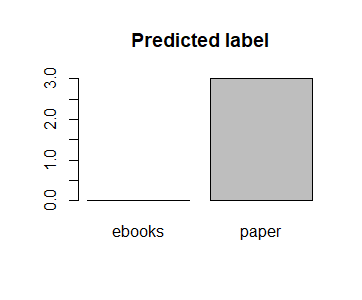
(Click to see a larger view.) |
From the bar charts, the model built by linear kernel makes better prediction than that built by radial kernel. The model built by radial kernel is very inefficient since the actual data is majorly in label "ebooks" while the label "ebooks" rarely appears in the prediction.
| Top 20 Features by Linear Kernel | Top 20 Features by Radial Kernel |
|---|---|
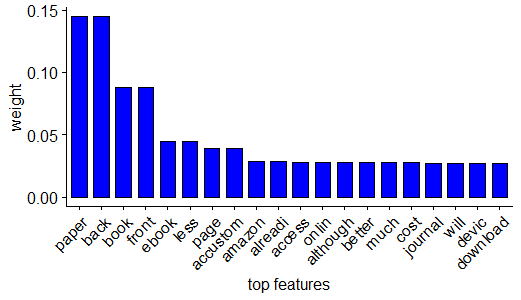
(Click to see a larger view.) |
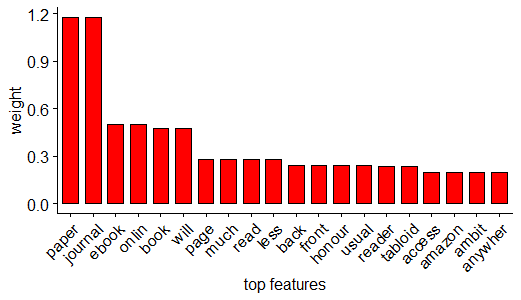
(Click to see a larger view.) |
The top five features are "paper", "back", "book", "front" and "ebook" in the model built by linear kernel and the top five features are "paper", "journal", "ebook", "online" and "book" in the model built by radial kernel.
| Confusion Matrix by Linear Kernel | Confusion Matrix by Radial Kernel |
|---|---|

(Click to see a larger view.) |

(Click to see a larger view.) |
The accuracy of the model built by linear kernel is 100%, while the accuracy of the model built by radial kernel is 33.33%. SVM model built by linear kernel is better than that built by radial kernel, which is the same as the result of bar charts above.
3) SVM in Python for Record Data: Click here to get Python code.
| Confusion Matrix by Linear Kernel | Confusion Matrix by Polynomial Kernel | |
|---|---|---|
| Cost=1 |
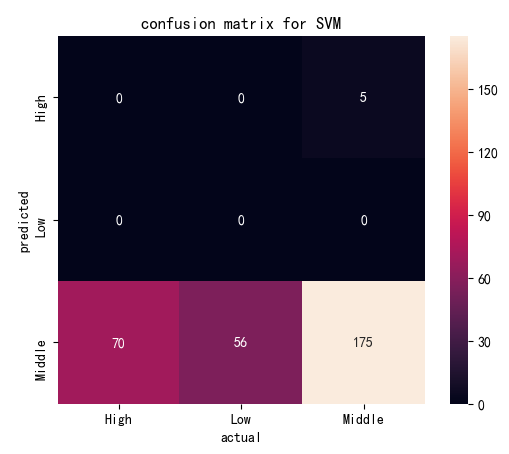
(Click to see a larger view.) |
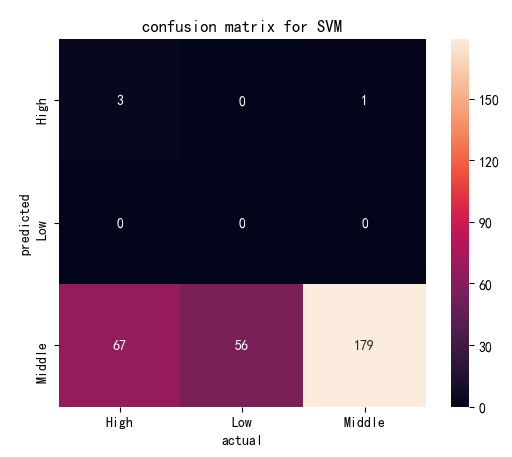
(Click to see a larger view.) |
| Cost=10 |
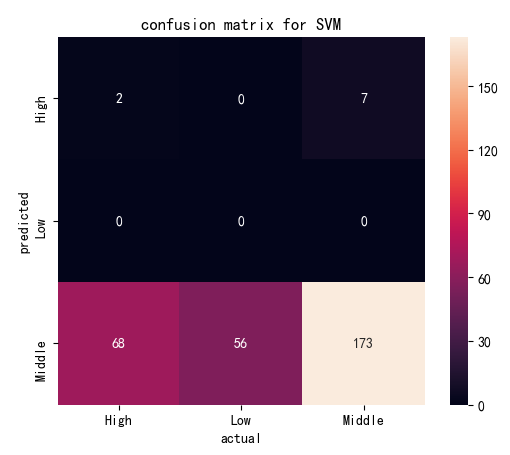
(Click to see a larger view.) |
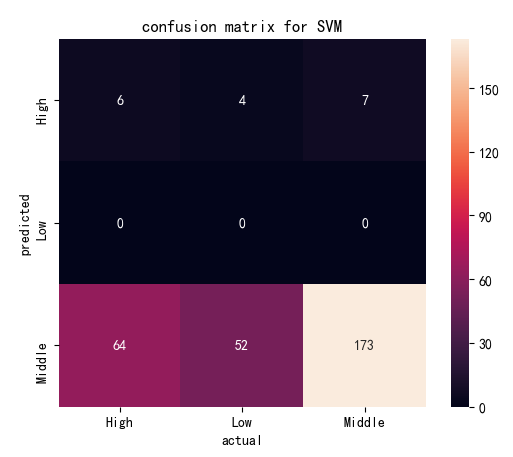
(Click to see a larger view.) |
| Cost=100 |
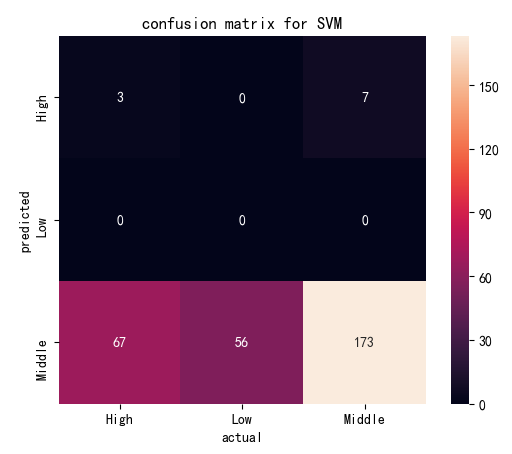
(Click to see a larger view.) |
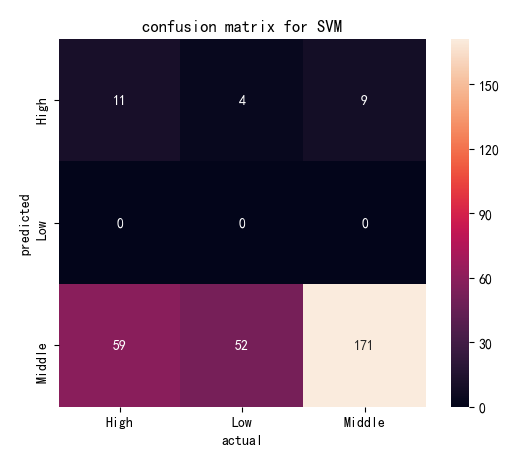
(Click to see a larger view.) |
The accuracy of the model built by linear kernel with cost=1 and cost=10 is 57.19%, and that with cost=100 is 57.52%, slightly better than the first two models, which indicates that the best cost for model built by linear kernel is 100. The accuracy of the model built by polynomial kernel with cost=1 and cost=100 is 59.48%, and that with cost=10 is 58.50%, slightly worse than the first two models. The best costs for model built by polynomial kernel are 1 and 100. In addition, SVM models built by polynomial kernel are slightly better than those built by linear kernel, with higher accuracy.
| Accuracy Score by Linear Kernel | Accuracy Score by Polynomial Kernel | |
|---|---|---|
| Cost=1 |
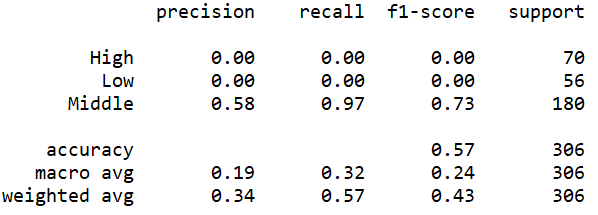
(Click to see a larger view.) |
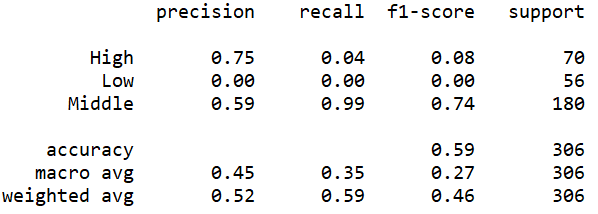
(Click to see a larger view.) |
| Cost=10 |
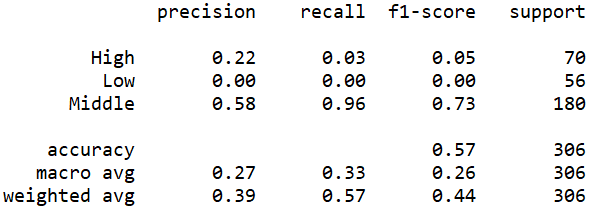
(Click to see a larger view.) |
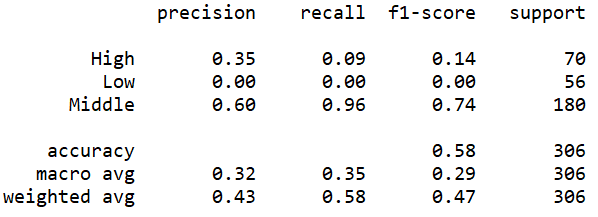
(Click to see a larger view.) |
| Cost=100 |
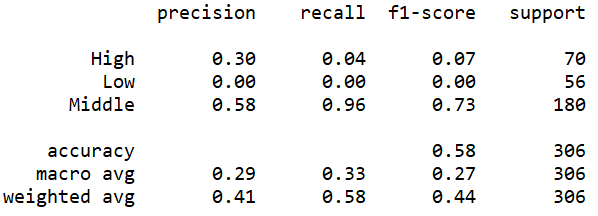
(Click to see a larger view.) |
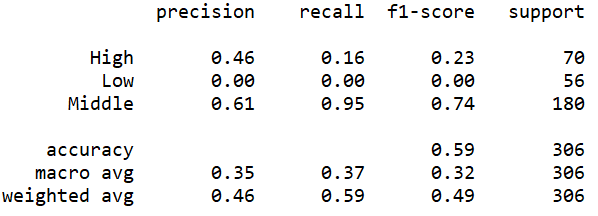
(Click to see a larger view.) |
The accuracy can be observed from these screenshots above. In addition, three measures, precision, recall and f1-score can also be observed. F1-score is the synthesis of precision and recall, which is more reliable. The f1-scores of the models built by polynomial kernel are slightly higher than those of the models built by linear kernel. Thus, the models built by polynomial kernel make better prediction than those built by linear kernel, which is the same as the result of the confusion matrix.
4) SVM in Python for Text Data: Click here to get Python code.
| Wordcloud for E-books | Wordcloud for Paper Books |
|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
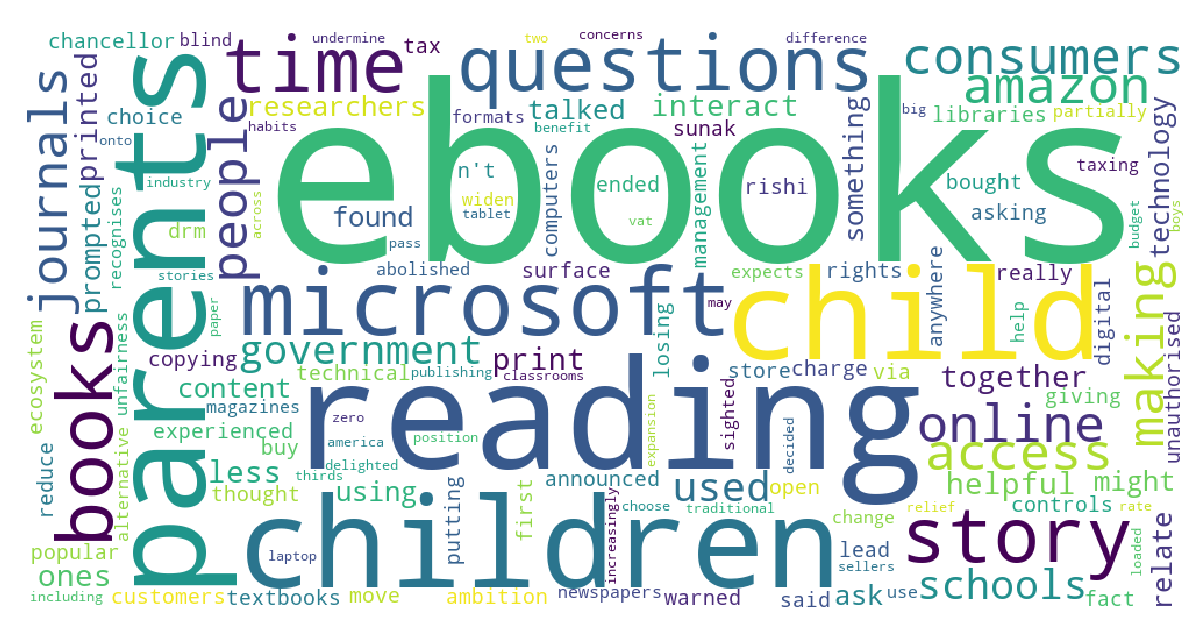
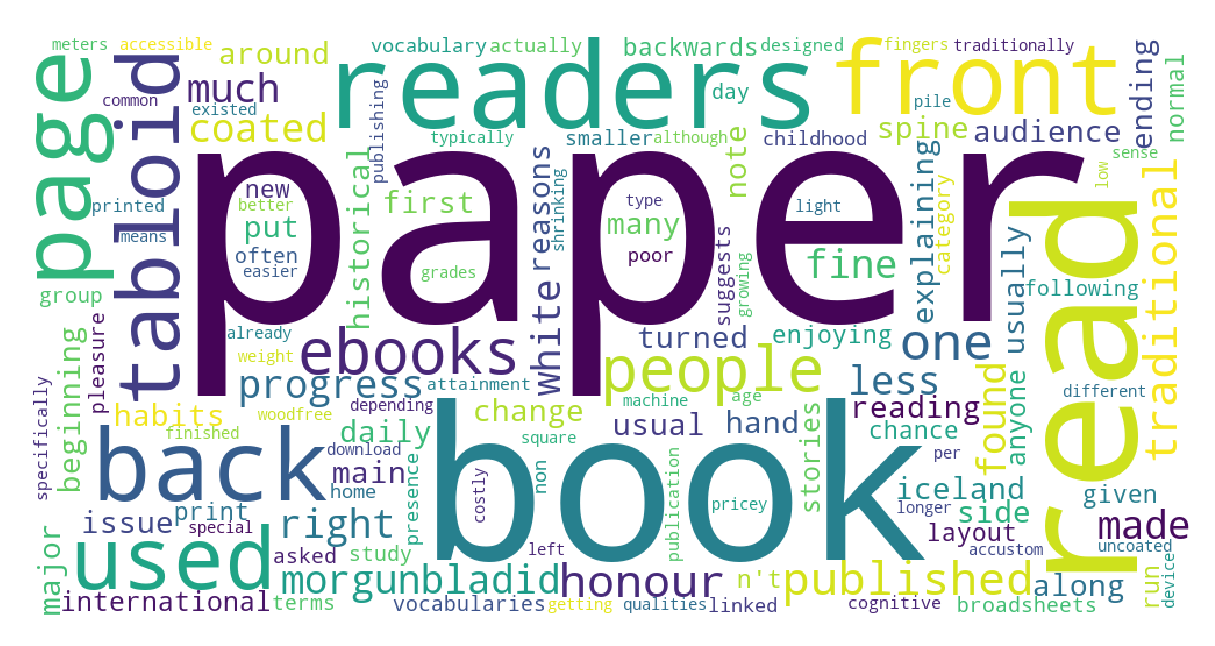
The main topics of BBC news related to e-books are children, parents, microsoft, time and story. The main topics of BBC news related to paper books are reader, page and tabloid.
| Result of SVM by Linear Kernel | Result of SVM by Gaussian Kernel |
|---|---|

(Click to see a larger view.) |

(Click to see a larger view.) |
The model built by linear kernel predicts two "ebooks" and one "paper", two of them are correct and one is wrong. The model built by Gaussian kernel predicts three "paper", while their actual labels are all "ebooks". Thus, SVM model built by linear kernel is better than that built by Gaussian kernel.
| Margin of SVM | Top 10 Positive & Negative Features |
|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
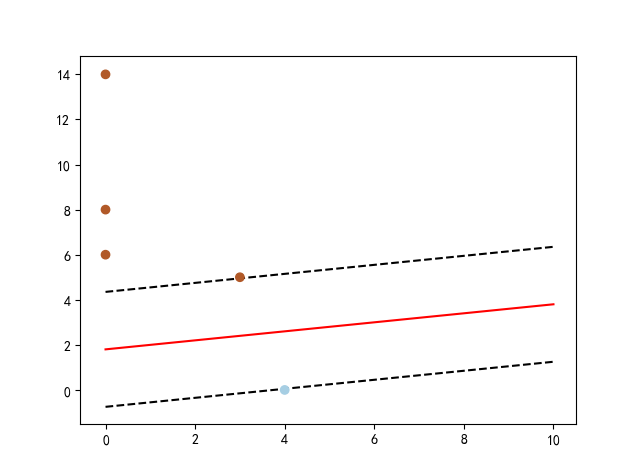
The goal of SVM is to maximize the margin between different classes and create the best separation. Margin is the distance between two parallel boundary lines, which are the dotted lines in the plot. The red line in the plot is the best separation between two classes "ebooks" and "paper".
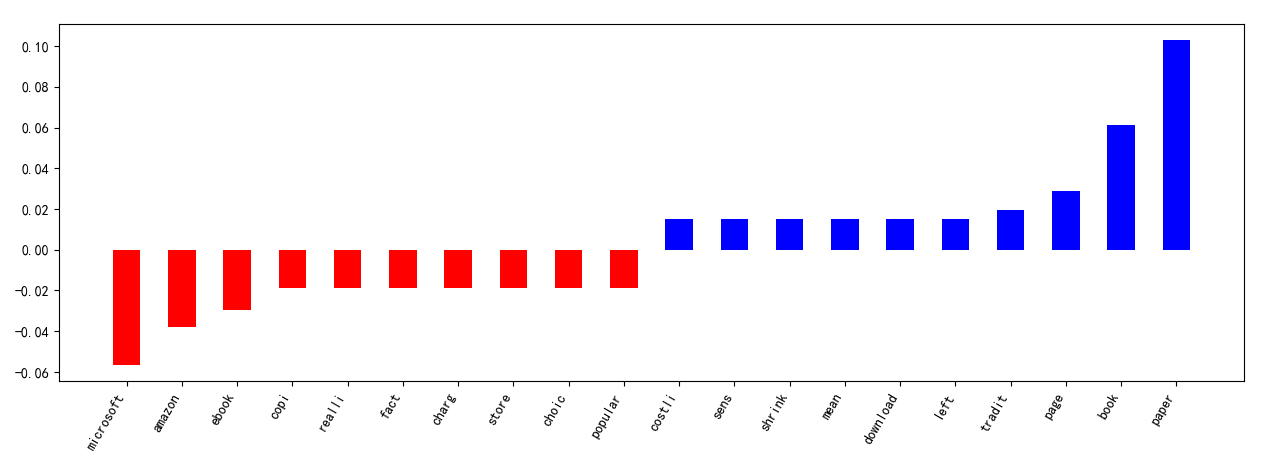
The top three positive features are "paper", "book" and "page" in the model built by linear kernel and the top three negative features are "microsoft", "amazon" and "ebook".
| Confusion Matrix by Linear Kernel | Confusion Matrix by Gaussian Kernel |
|---|---|
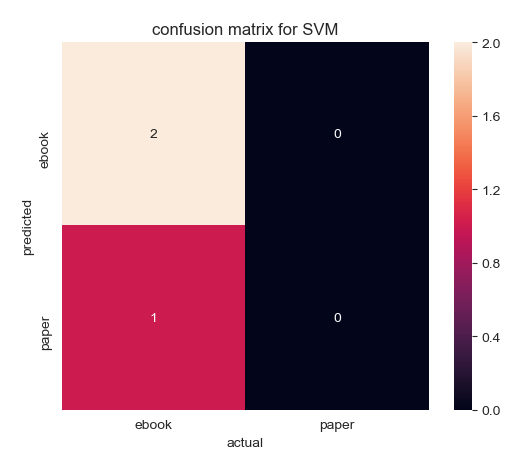
(Click to see a larger view.) |
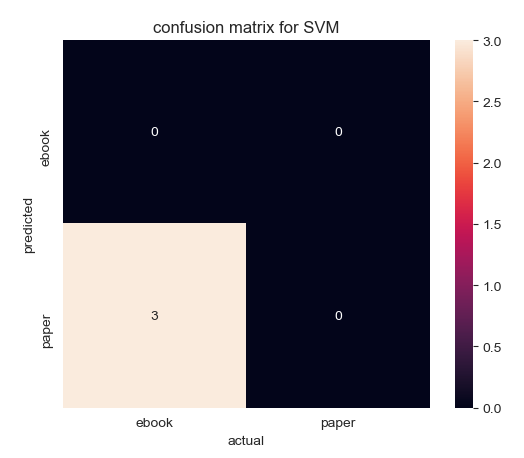
(Click to see a larger view.) |
The accuracy of the model built by linear kernel is 66.67%, while the accuracy of the model built by Gaussian kernel is 0. Thus, the model built by linear kernel is better than that built by Gaussian kernel, which is the same as the result of SVM.
| Accuracy Score by Linear Kernel | Accuracy Score by Gaussian Kernel |
|---|---|
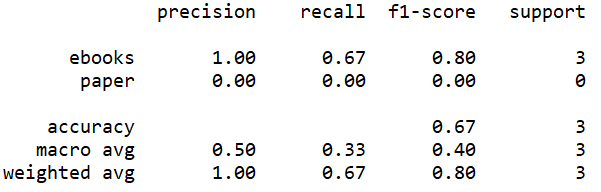
(Click to see a larger view.) |
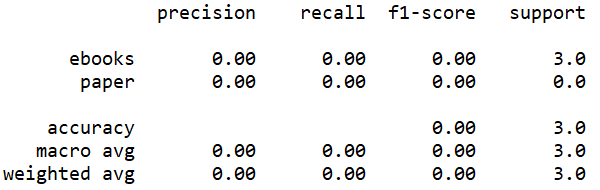
(Click to see a larger view.) |
The accuracy can be observed from the screenshots above. In addition, three measures, precision, recall and f1-score can also be observed. F1-score is the most reliable one. The f1-score of the model built by linear kernel is higher than that of the model built by Gaussian kernel. Thus, the model built by linear kernel makes better prediction than that built by Gaussian kernel, which is the same as the result of the confusion matrix.
5) Conclusion
In the first and third part, from SVM for record data, more than half of the books in Amazon are in "Middle" rating, which is from 4 to 4.5. The number of reviews of most books is less than 300. For books that have more than 300 reviews, their ratings are higher, hardly anything below 4. As for price, about 90% of the books cost more than 100 dollars, while more expensive books gain higher ratings.
In the second and fourth part, from SVM for text data, word "ebooks" occurs in every document labeled as "ebooks" and one of that labeled as "paper". Word "books" occurs in three of the documents labeled as "ebooks" and two of that labeled as "paper". In addition, the main topics of BBC news related to e-books are children, parents, microsoft, time and story, and the main topics of BBC news related to paper books are reader, page and tabloid. Among the words in BBC news, "paper", "book" and "page" are the top three positive features, and "microsoft", "amazon" and "ebook" are the top three negative ones.