
| Before Cleaning | During Cleaning | After Cleaning |
|---|---|---|
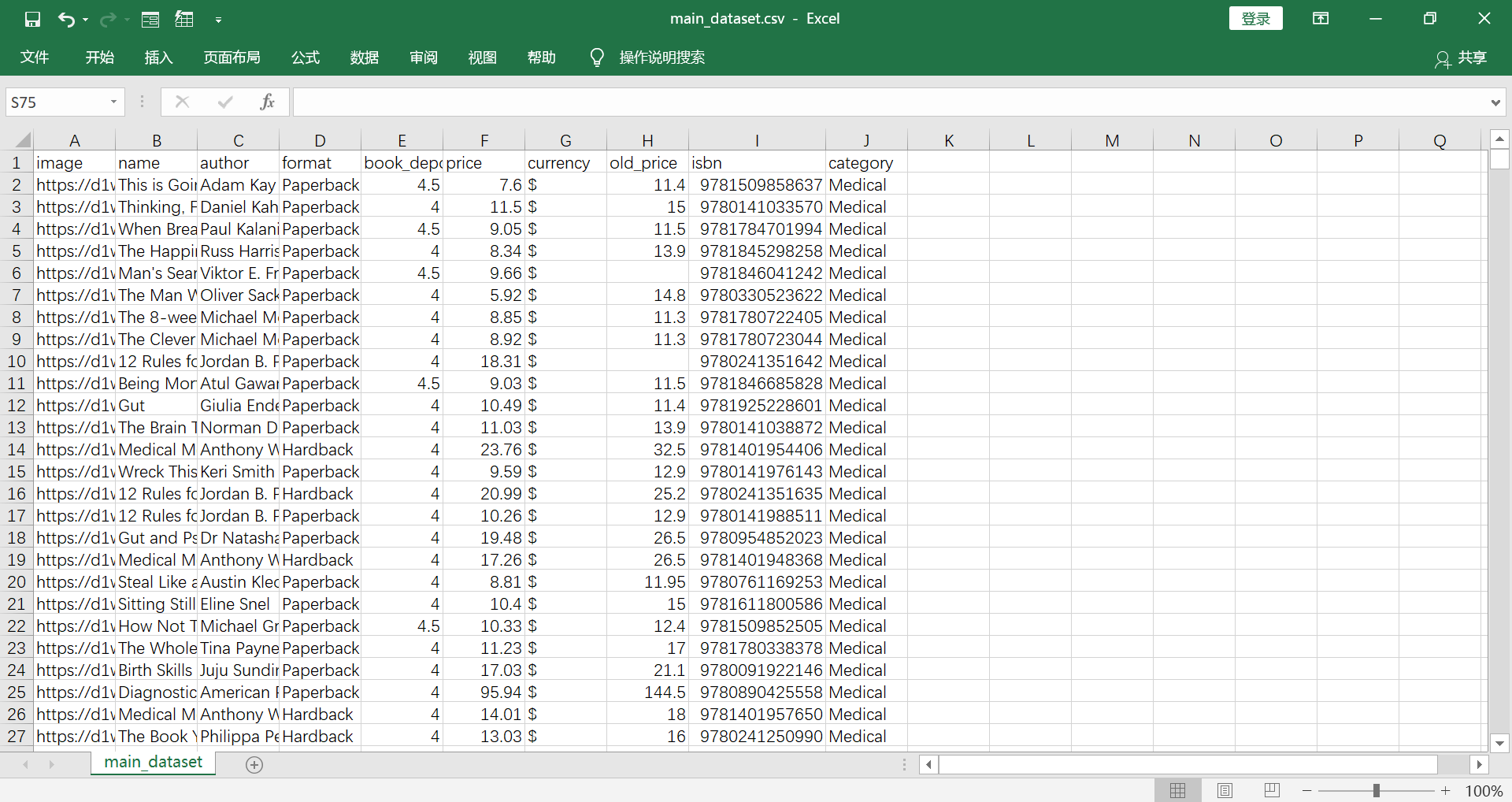
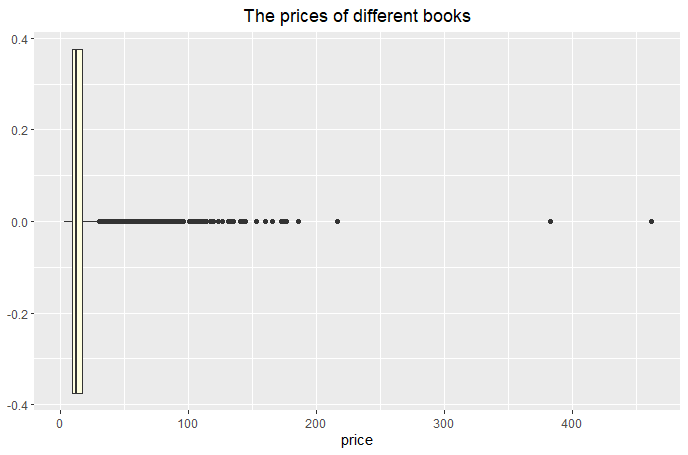
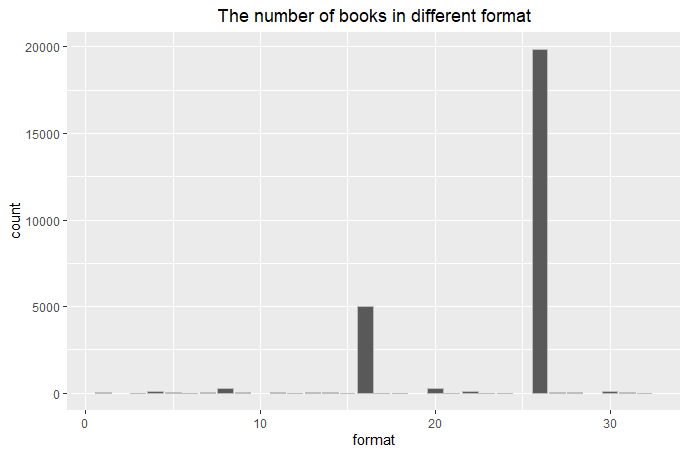
(Click to see a larger view.) |
1) Remove the columns "image", "name", "author", "currency" and "isbn" which are useless to further analysis.
2) Use as.numberic to convert the type of "price" from factor to numeric data. 3) Remove the rows that have empty data. 4) For nominal data "category" and "format", use numbers to replace the data. One number represents one book category or format. 5) Find out the potential outliers and remove them. 6) This dataset has 25,000+ rows after above cleaning. Choose some portions of rows randomly for further analysis. **Click here to get R Code. |
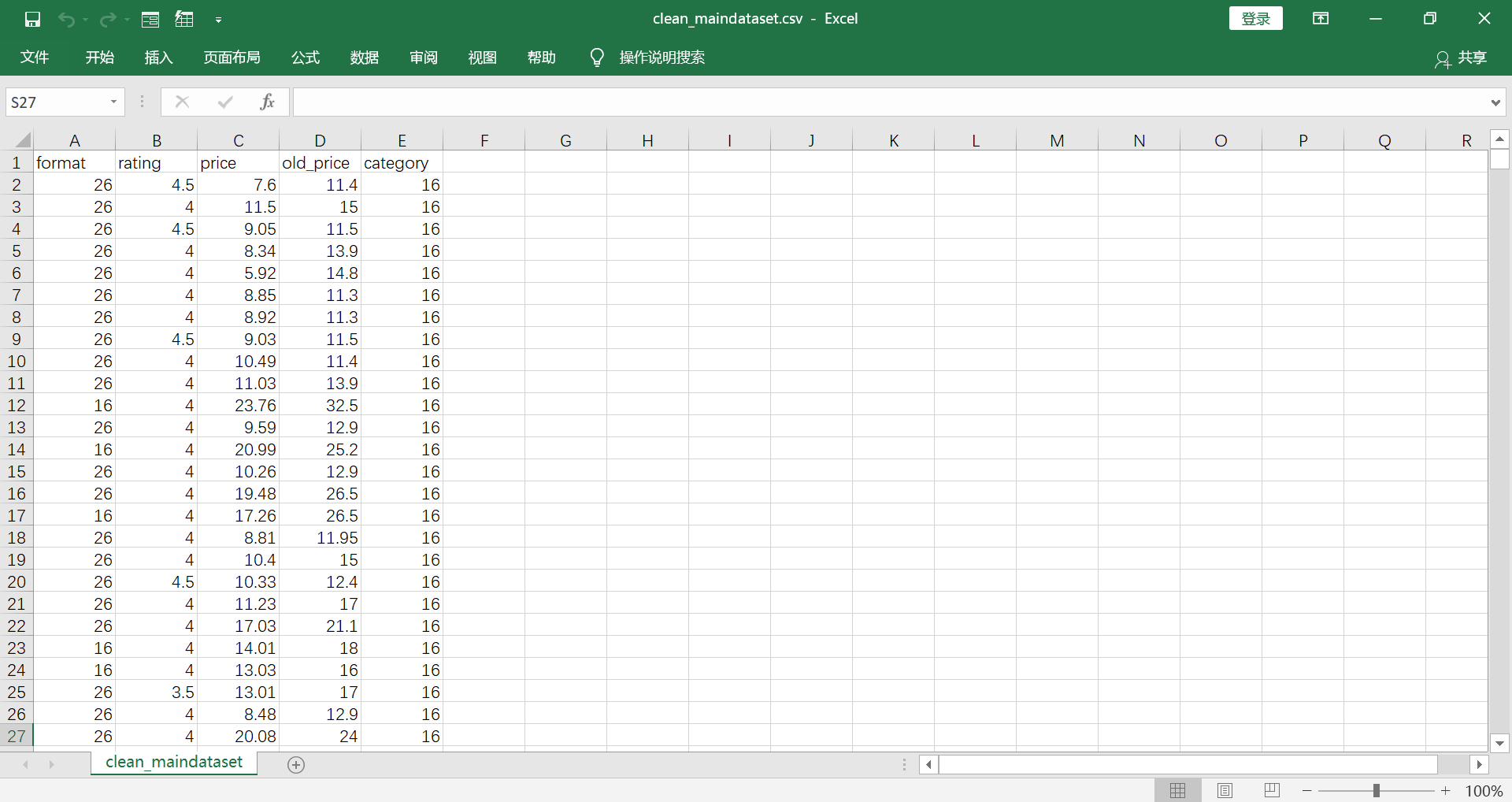
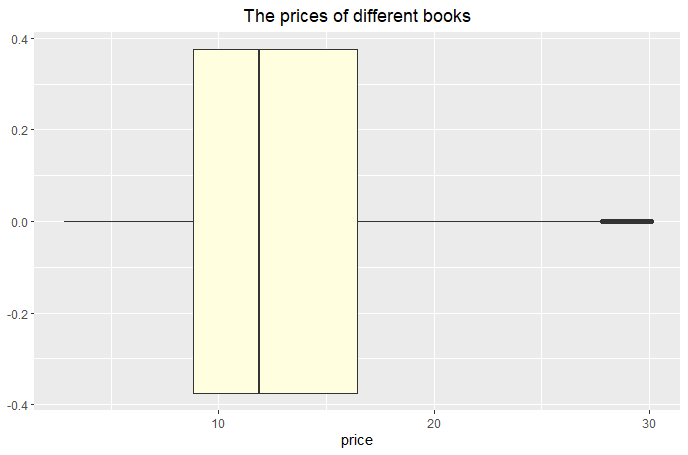
(Click to see a larger view.) |
(Click to see a larger view.) |
1) Read the txt file to a dataframe.
2) Remove the columns "url", "urlToImage", "author", "publishedAt", "name" and "id" which are useless to further analysis. 3) Tokenize, normalize and stem all of the Tweets that were loaded into a dataframe. 4) Remove the stopwords in the text data. 5) Count the frenquency of words. 6) Create a wordcloud of the most frequent words about reading on Twitter. **Click here to get Python Code. |
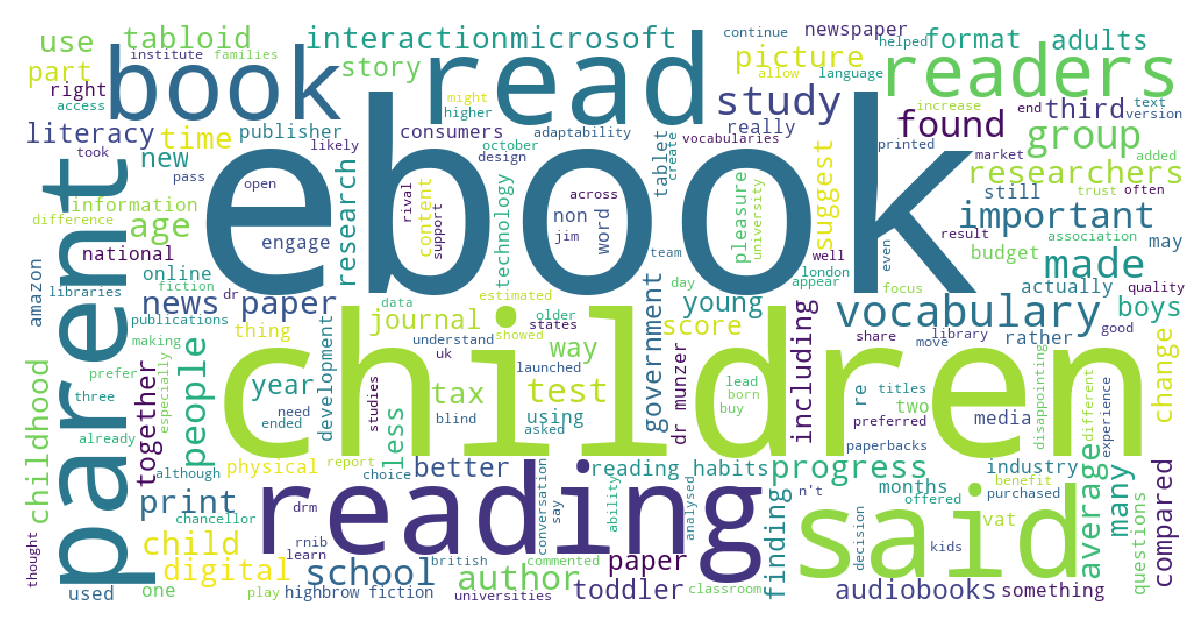
(Click to see a larger view.) |
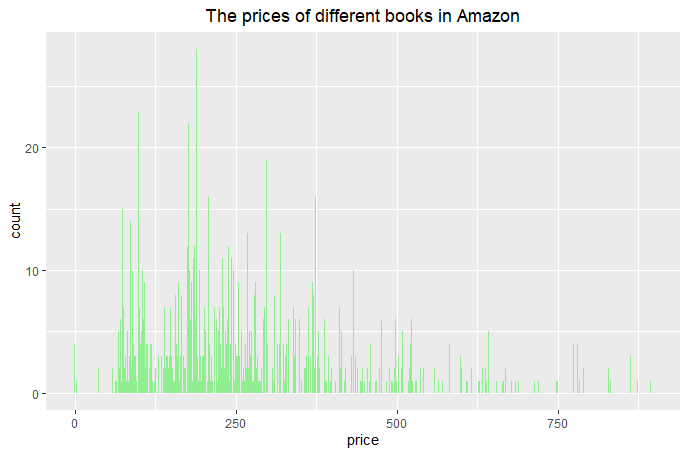
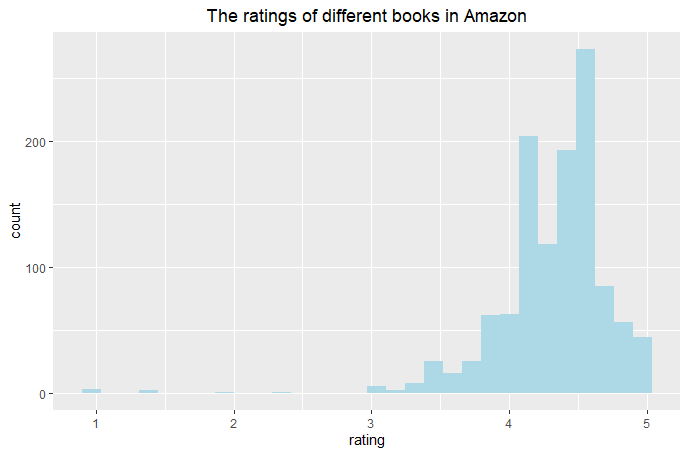
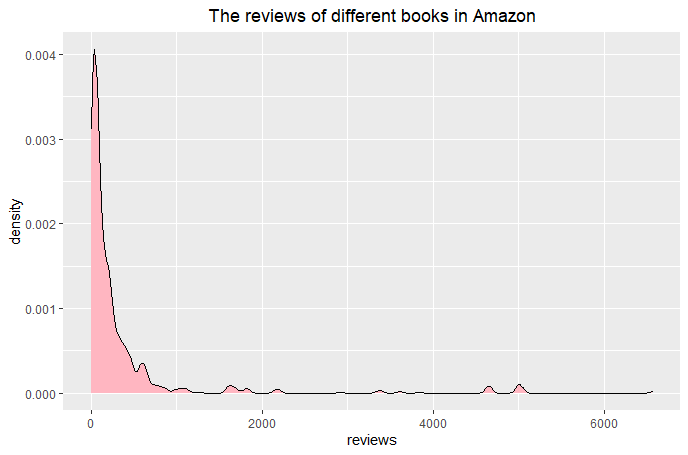
(Click to see a larger view.) |
1) Remove the columns "amazon_title", "amazon_author" and "amazon_isbn" which are useless to further analysis.
2) Use as.numberic to convert the type of "rating" and "reviews" from factor to numeric data. 3) Remove the rows that have empty data. 4) Find out the potential outliers and remove them. **Click here to get R Code. |
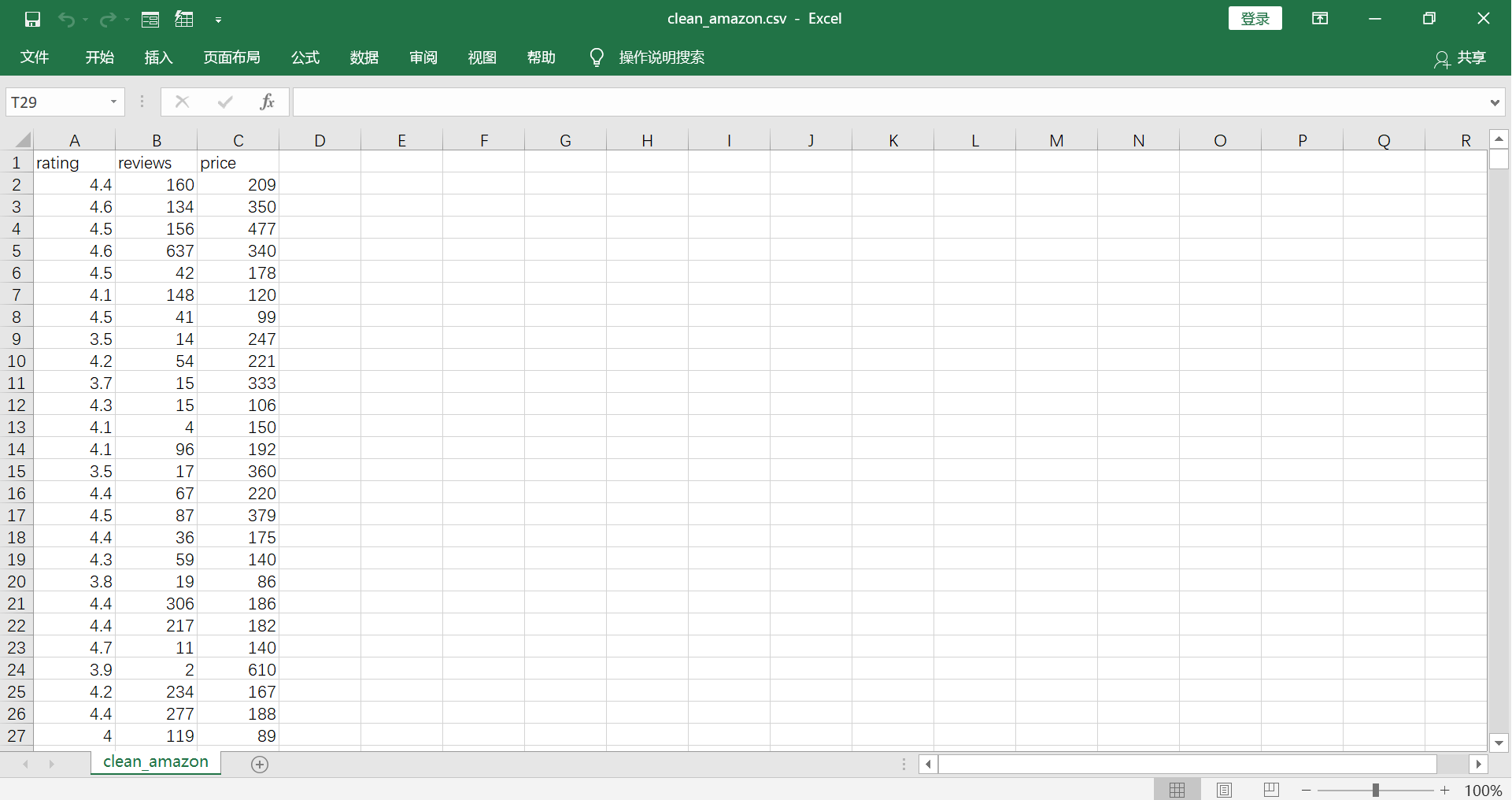
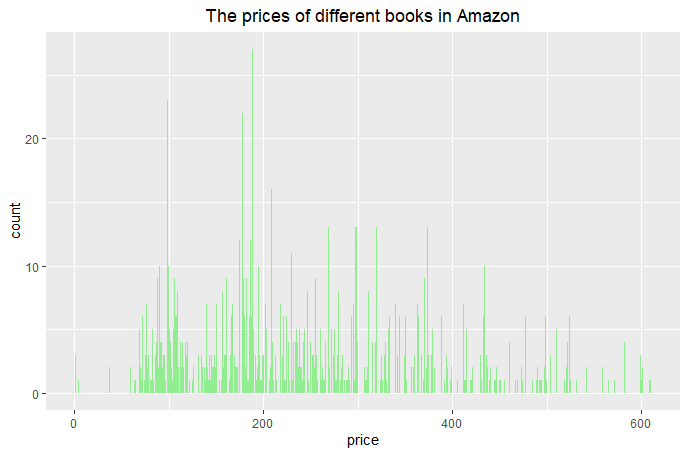
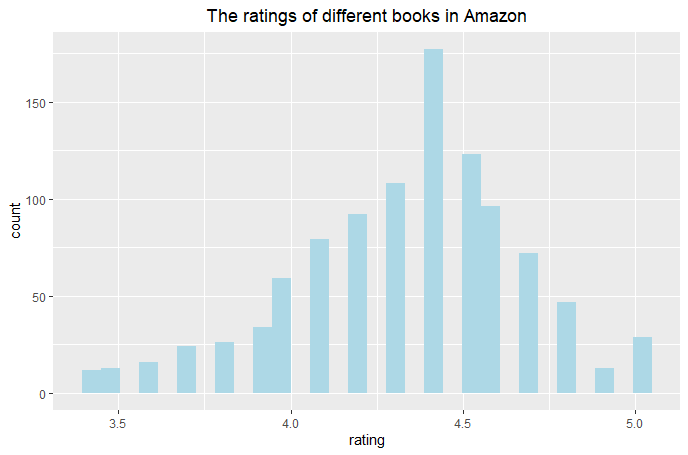
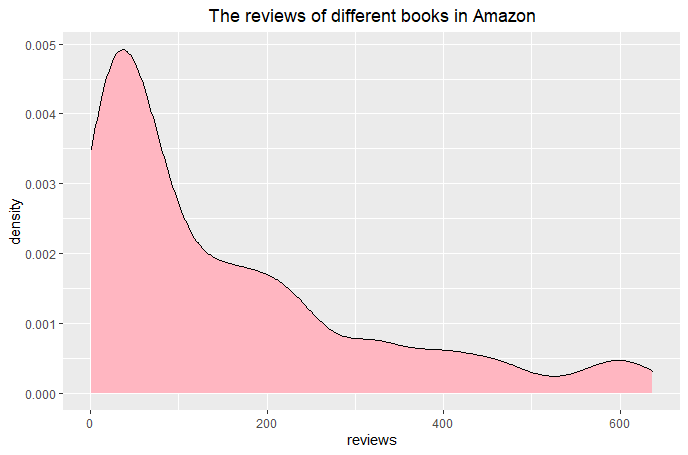
(Click to see a larger view.) |

(Click to see a larger view.) |
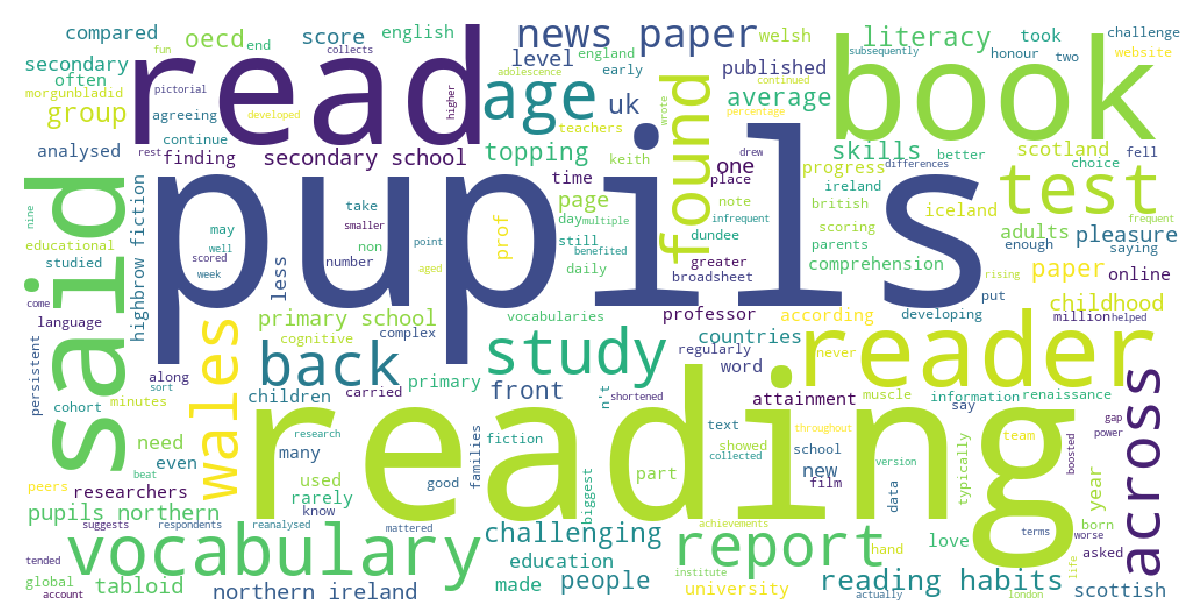
1) Tokenize, normalize and stem all of the BBCNews in the txt file.
2) Remove the stopwords in the text data. 3) Count the frenquency of words. 4) Create a wordcloud of the most frequent words about reading on BBCNews. **Click here to get Python Code. |

(Click to see a larger view.) |