
**Click here to get Record Data. Click here to get Text Data.
1) Clustering in Python: Click here to get Python code.
| k-value=2 | k-value=3 | k-value=4 | |
|---|---|---|---|
| For Record Data |
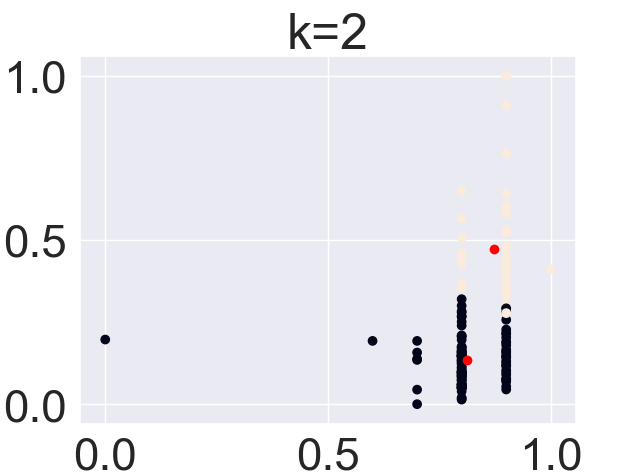
(Click to see a larger view.) |
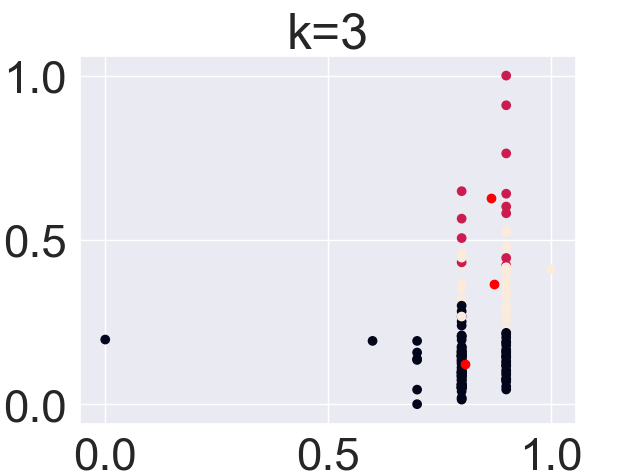
(Click to see a larger view.) |
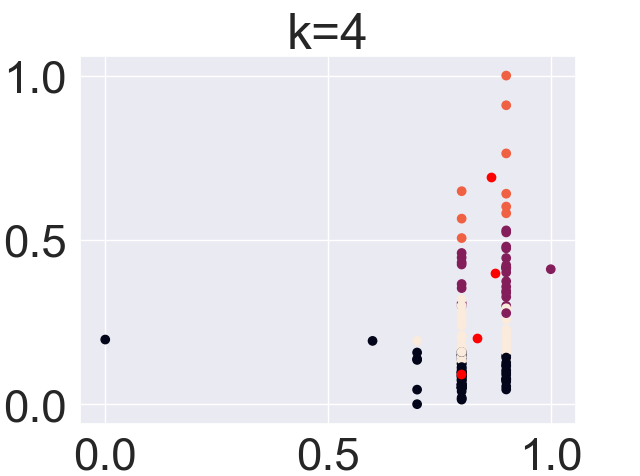
(Click to see a larger view.) |
| For Text Data |
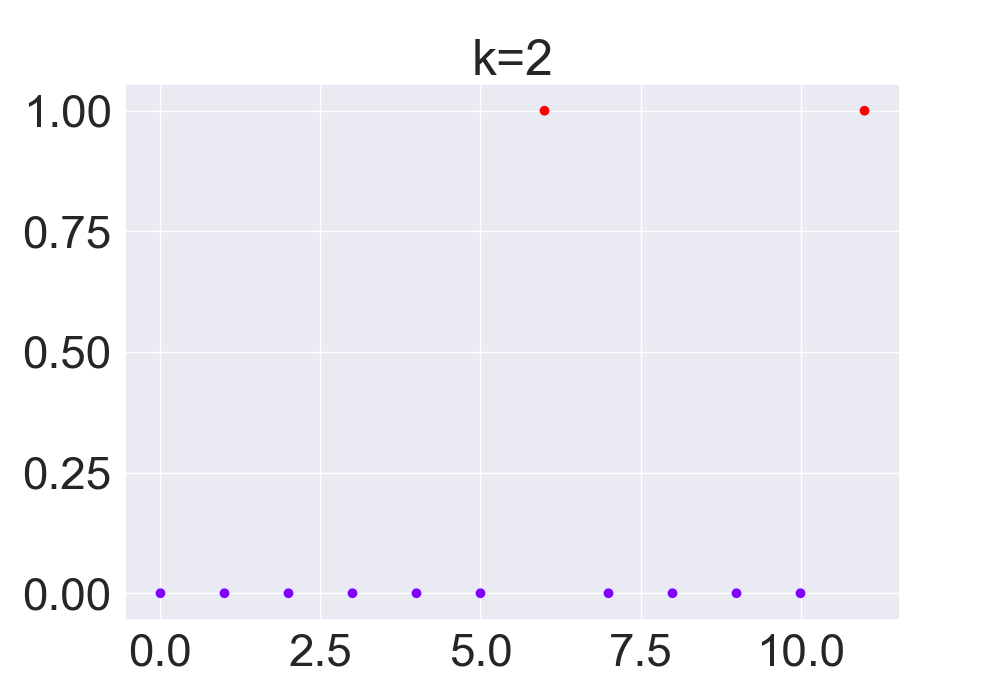
(Click to see a larger view.) |
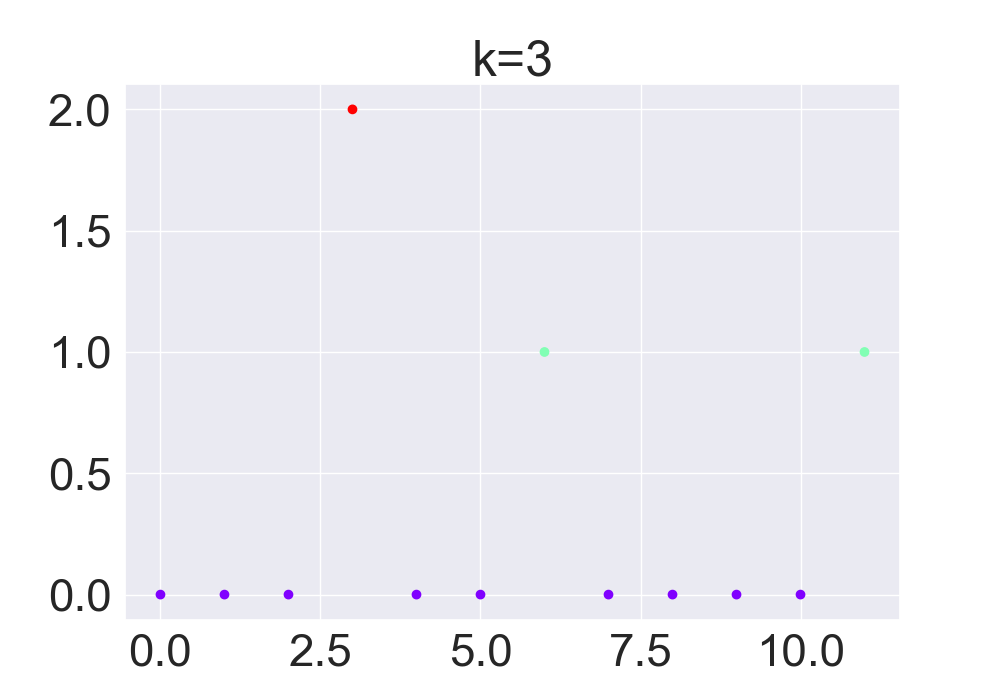
(Click to see a larger view.) |
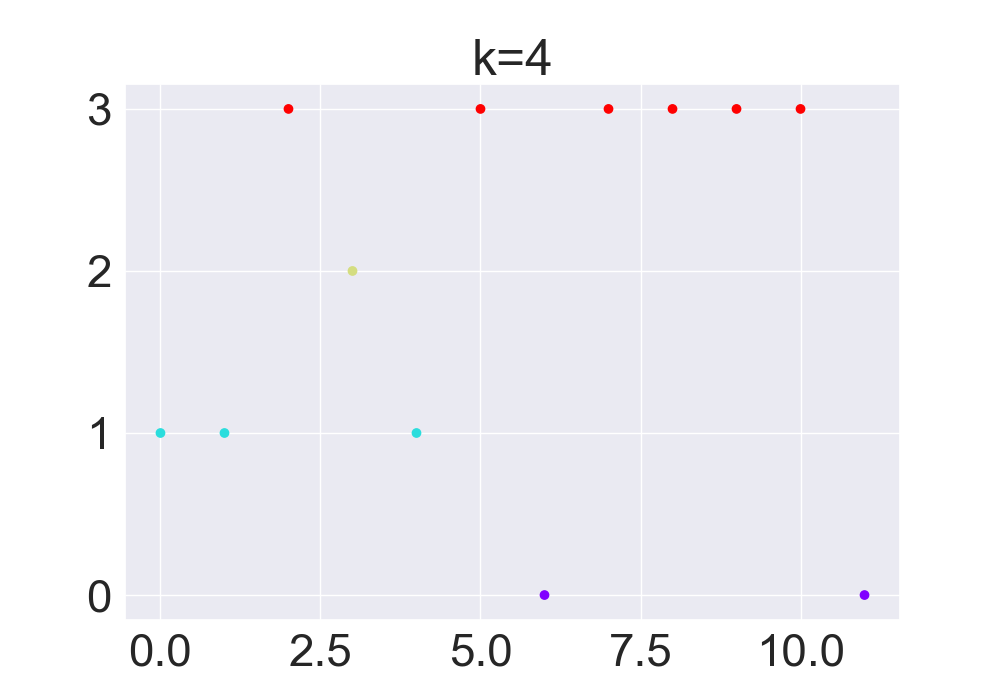
(Click to see a larger view.) |
For record data, the optimal k-value is 2. And for text data, the optimal k-value is 4.
| Manhattan Distance | Euclidean Distance | Cosine Similarity | |
|---|---|---|---|
| For Record Data |
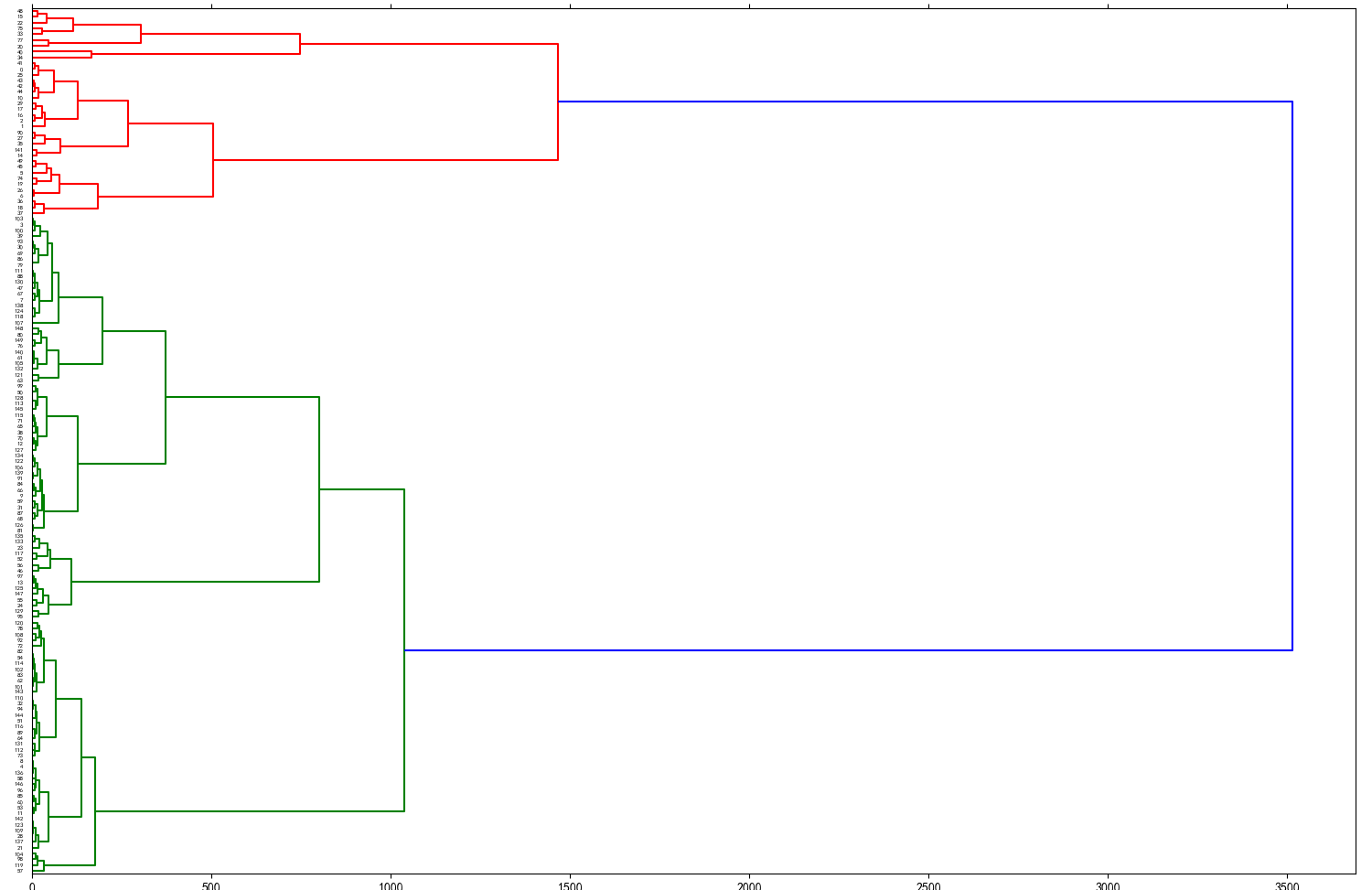
(Click to see a larger view.) The suggested k-value is 2. |
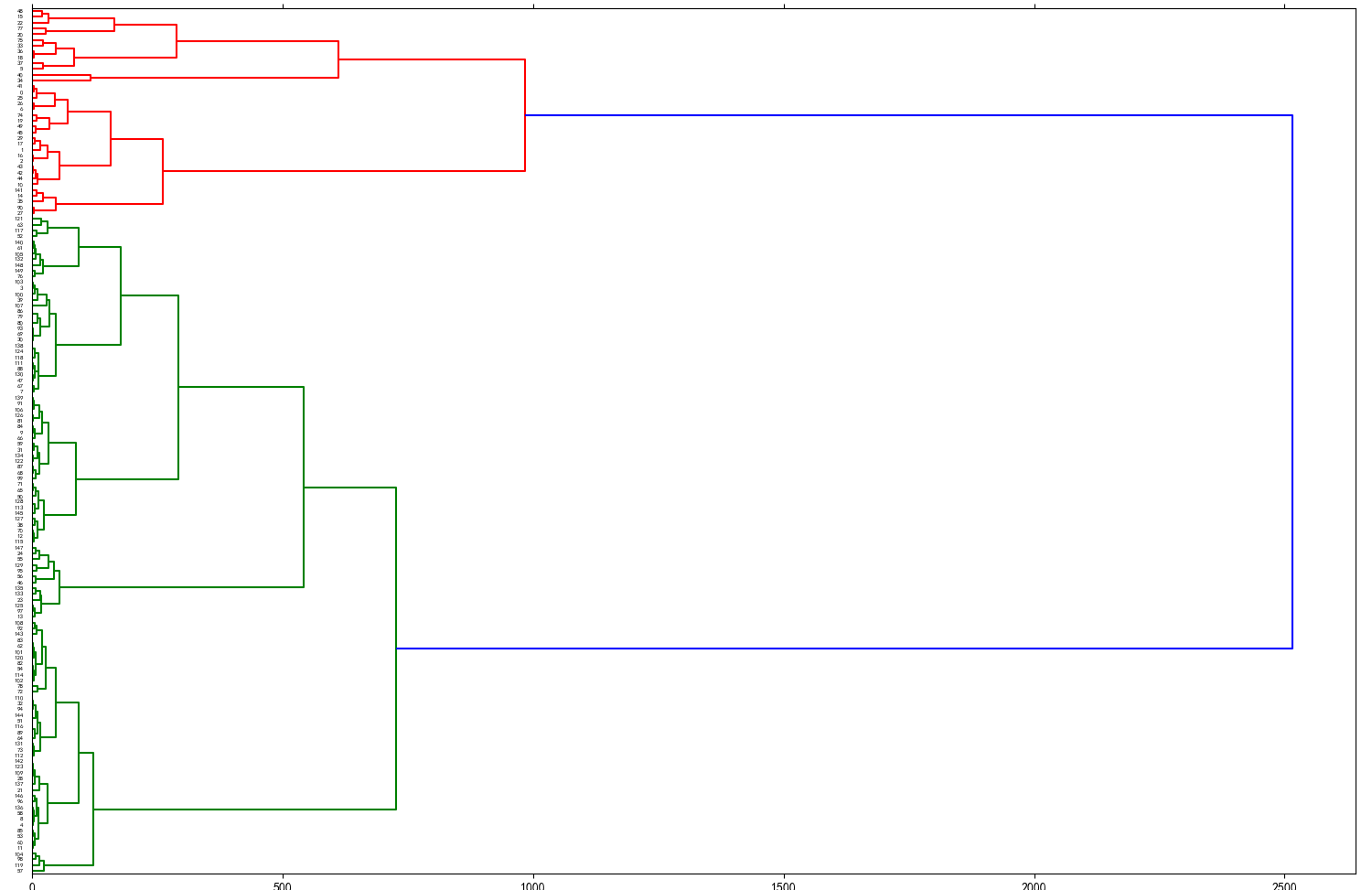
(Click to see a larger view.) The suggested k-value is 2. |
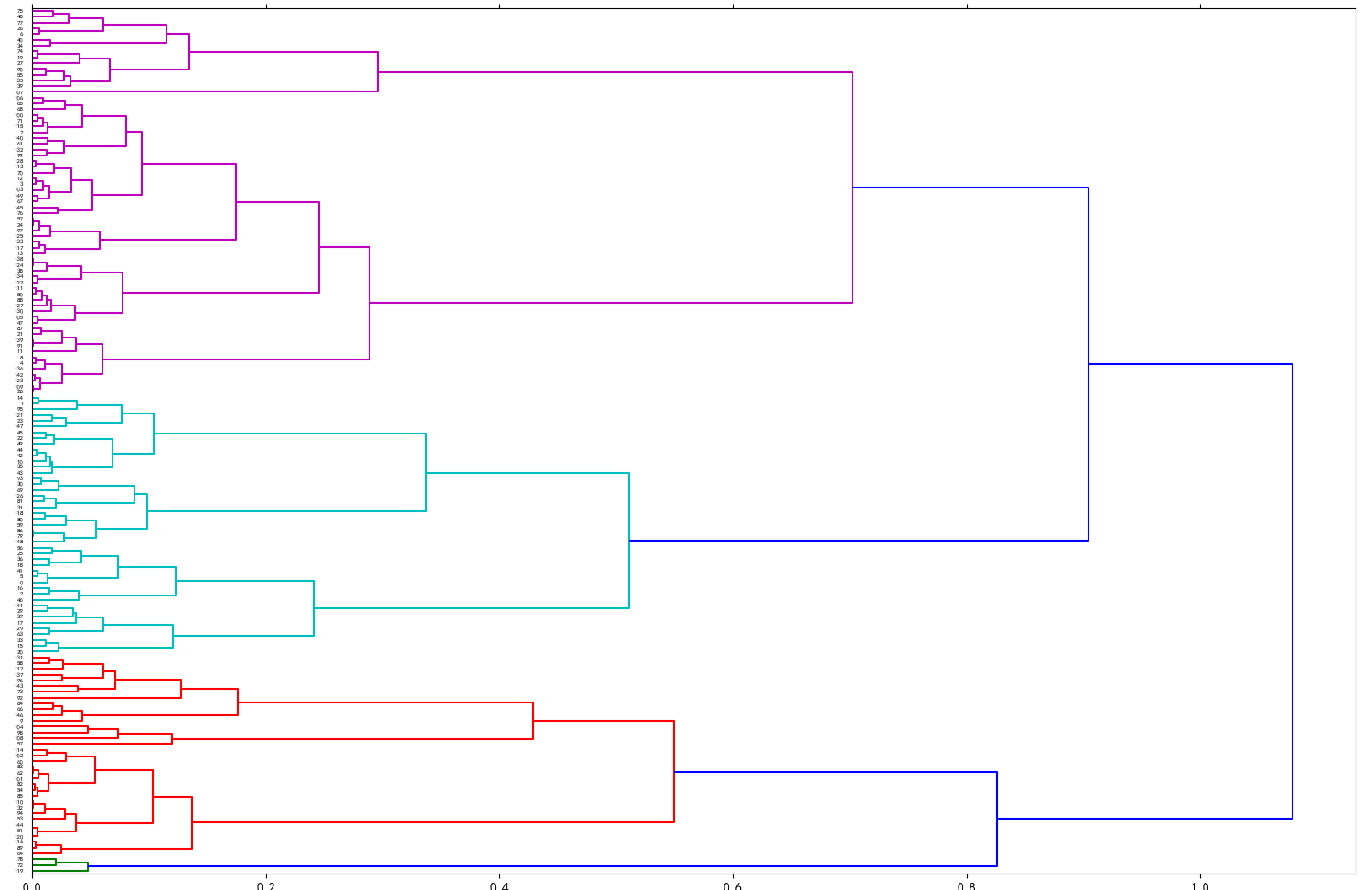
(Click to see a larger view.) The suggested k-value is 3. |
| For Text Data |
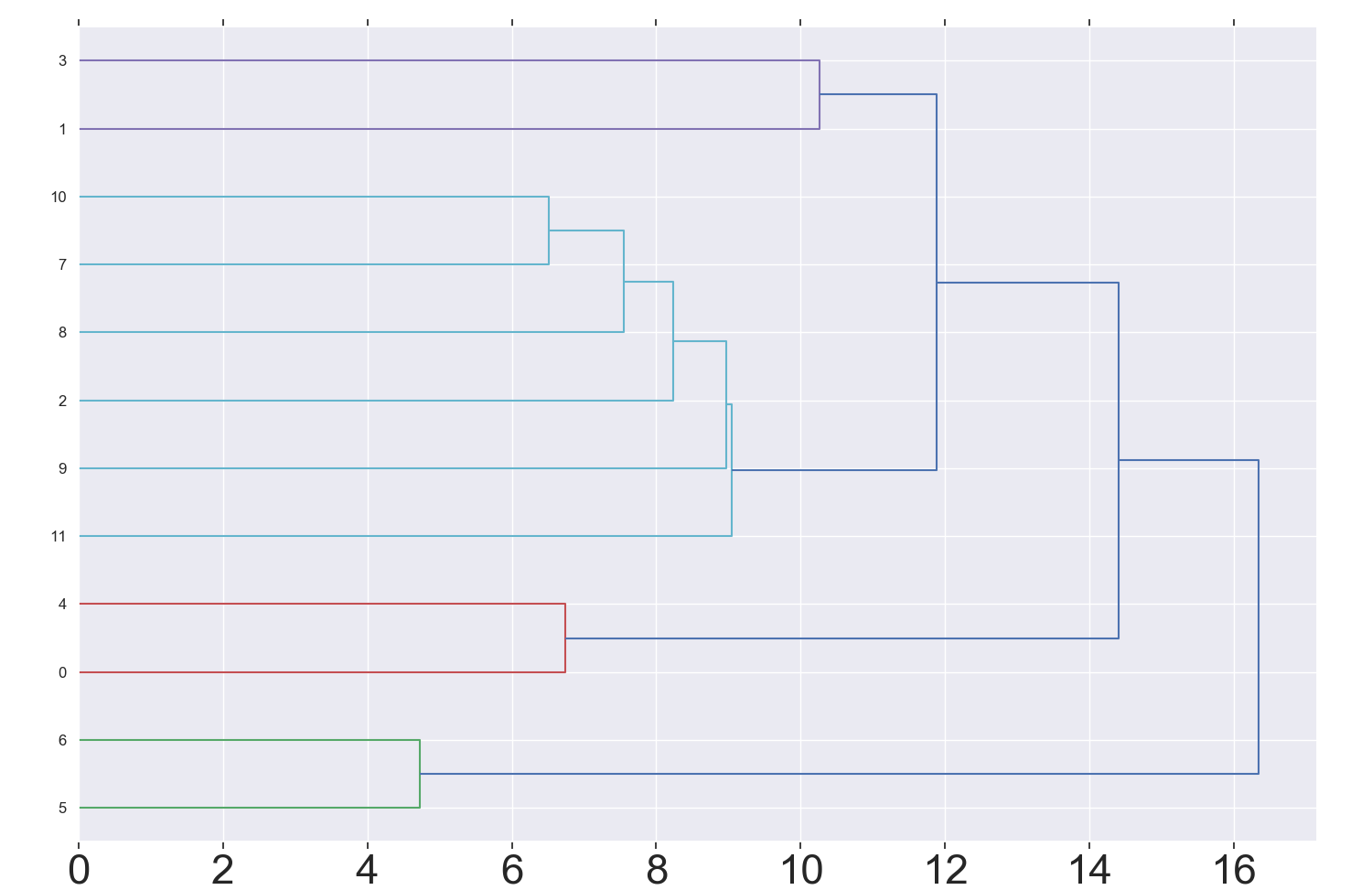
(Click to see a larger view.) The suggested k-value is 4. |
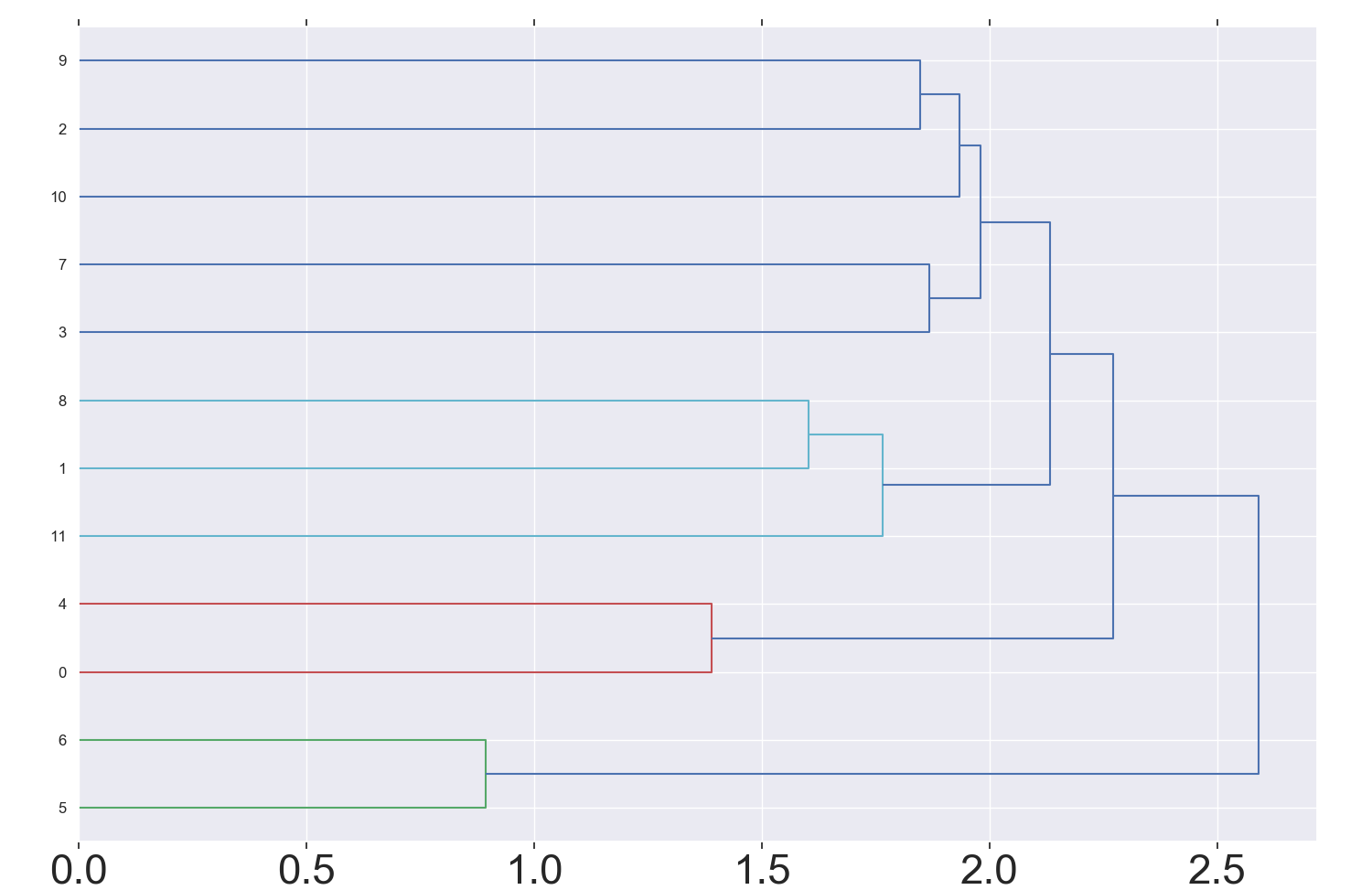
(Click to see a larger view.) The suggested k-value is 4. |
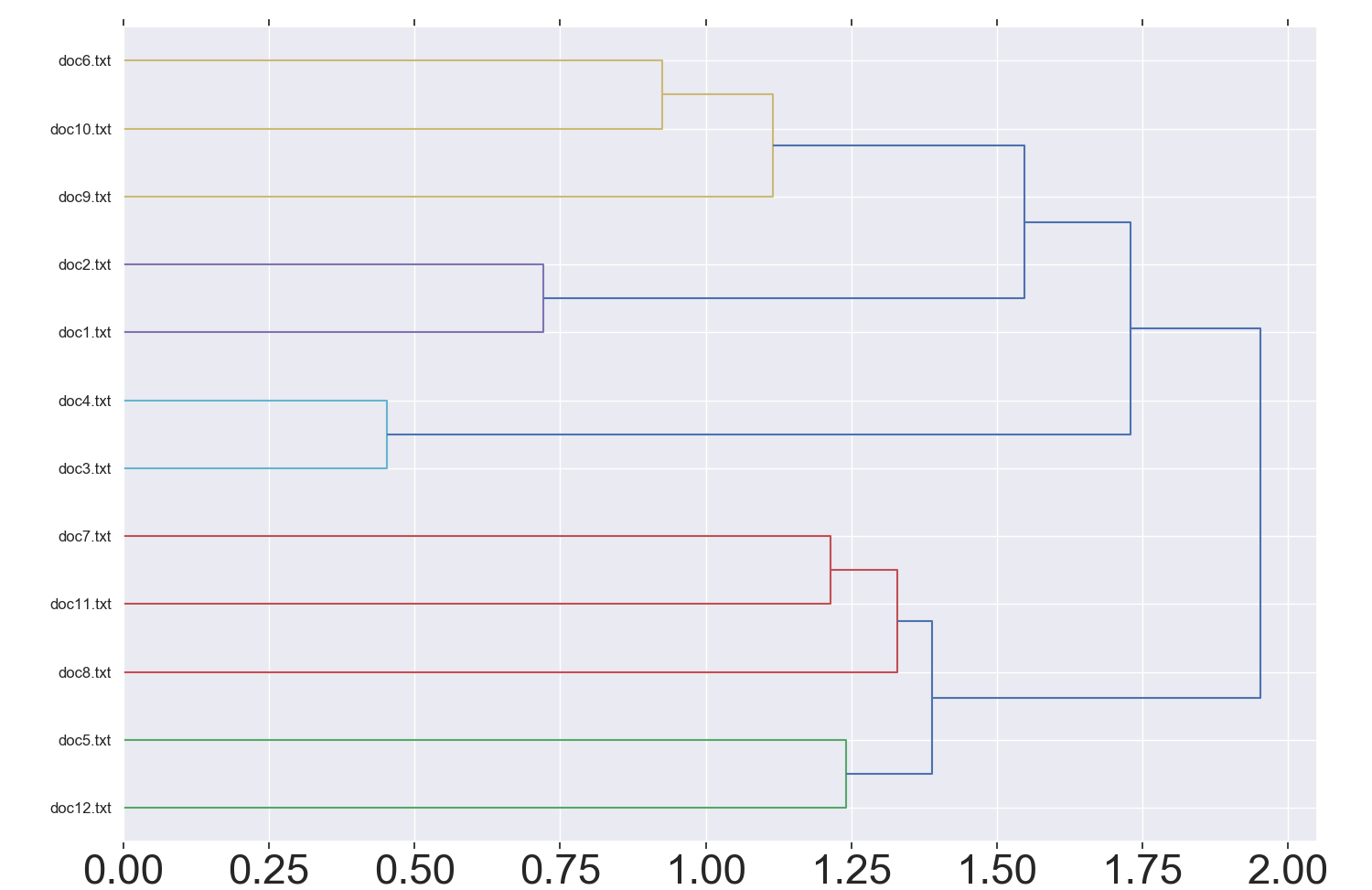
(Click to see a larger view.) The suggested k-value is 5. |
For both record and text data, Manhattan distance and Euclidean distance are more similar than Cosine similarity.
For record data, the optimal k-value is 2, and for text data, the optimal k-value is 4, which are the same as the previous results.
| For Record Data | For Text Data |
|---|---|

(Click to see a larger view.) |
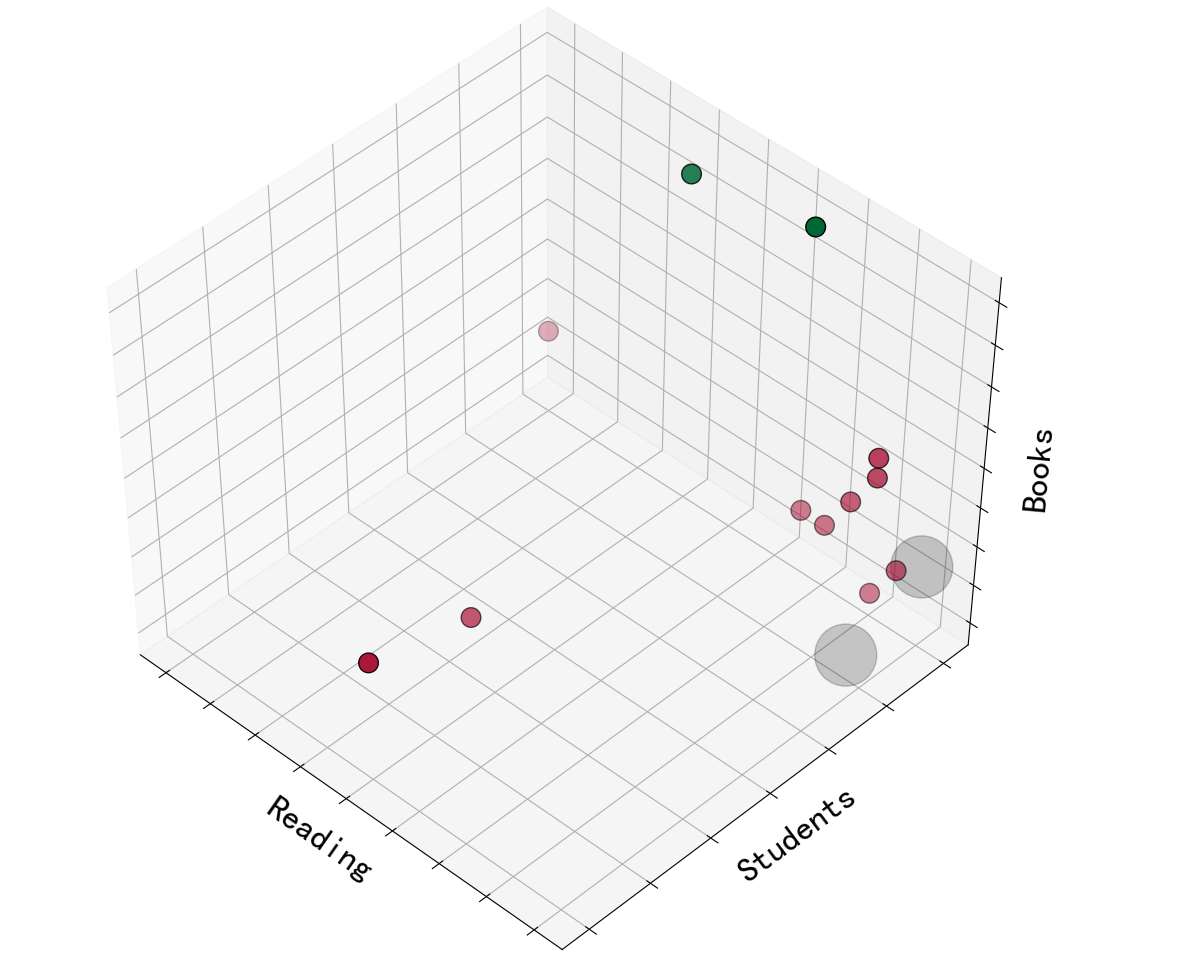
(Click to see a larger view.) |
For record data, the x, y, z labels of the 3D visualization are the book categories. And for text data, the x, y, z labels of the 3D visualization are the most frequent words.
| For Record Data | For Text Data |
|---|---|
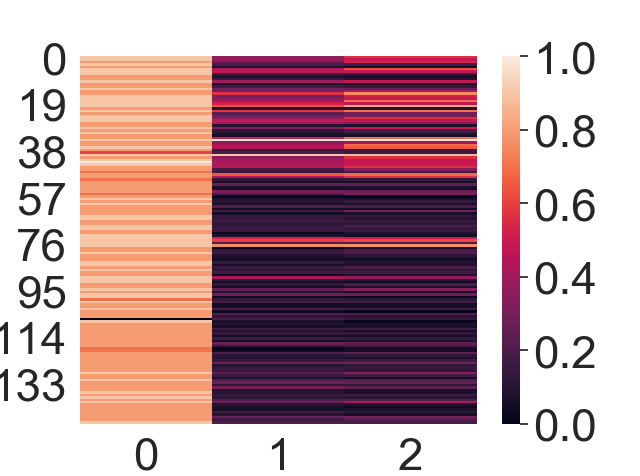
(Click to see a larger view.) |
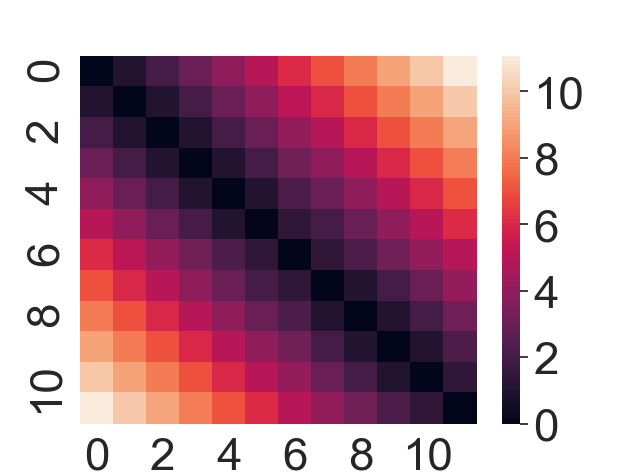
(Click to see a larger view.) |
For record data, the category 0, which is computing book, has a much higher correlation. And for text data, the first document and the tenth document have the highest correlation.
2) Clustering in R: Click here to get R code.
| Elbow | Silhouette | Gap Statistics | |
|---|---|---|---|
| For Record Data |
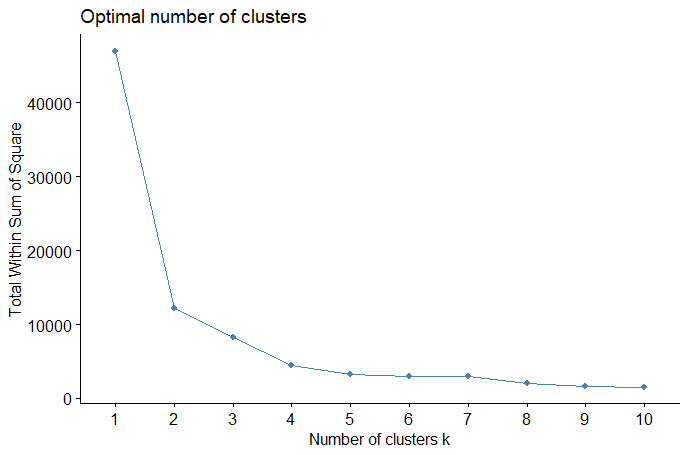
(Click to see a larger view.) The suggested k-value is 2. |
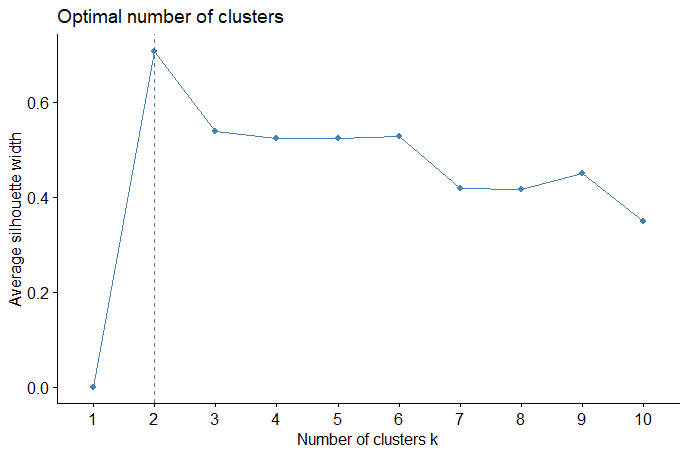
(Click to see a larger view.) The suggested k-value is 2. |
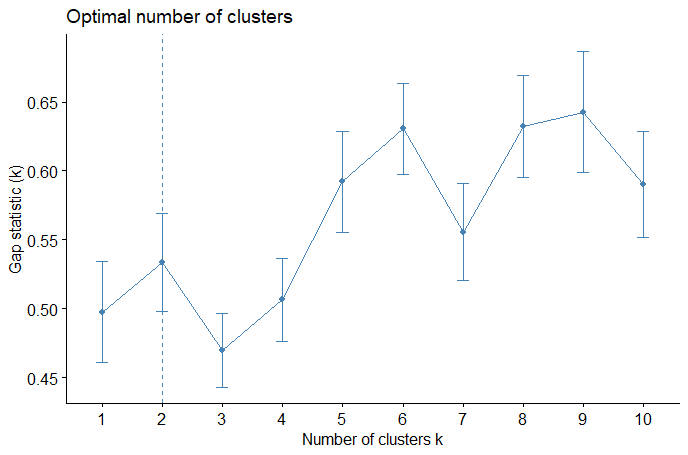
(Click to see a larger view.) The suggested k-value is 2. |
| For Text Data |
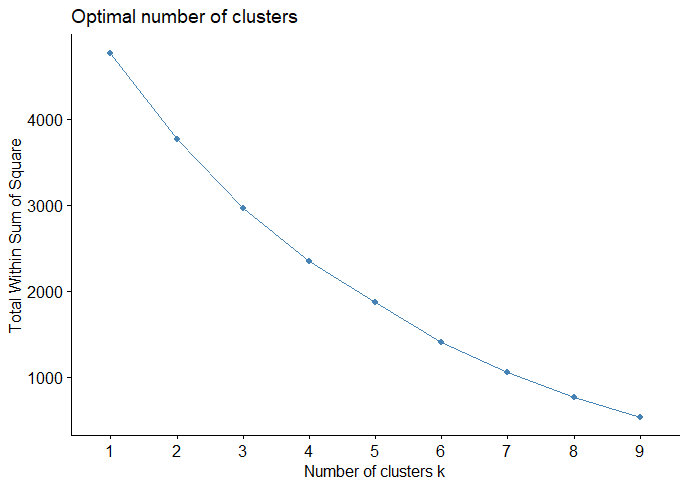
(Click to see a larger view.) The suggested k-value is 1. |
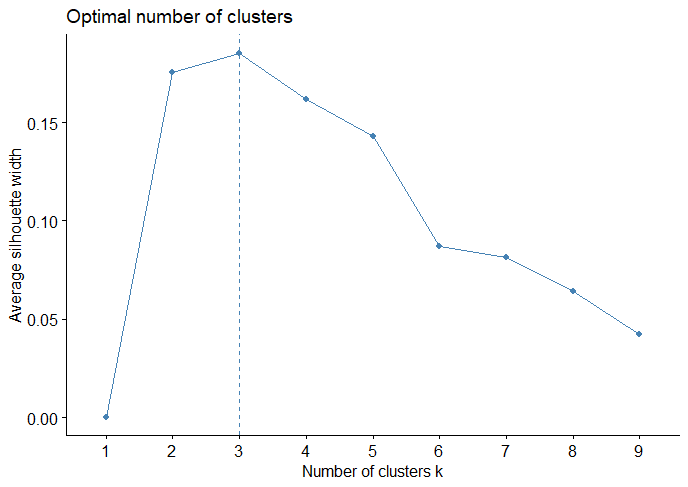
(Click to see a larger view.) The suggested k-value is 3. |
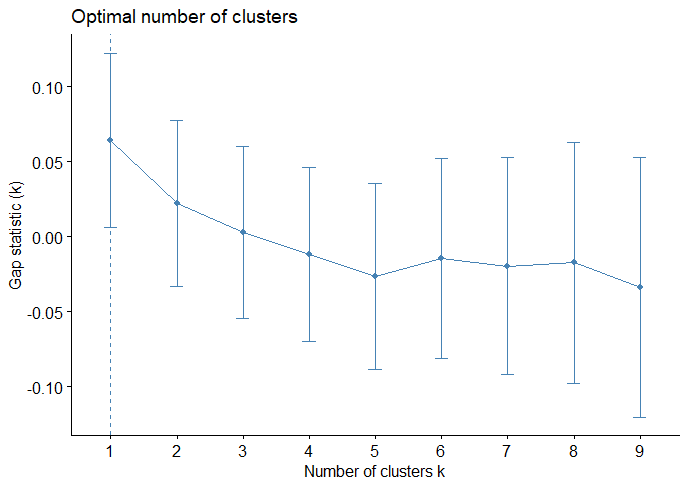
(Click to see a larger view.) The suggested k-value is 1. |
For record data, the optimal k-value is 2. For text data, the plots illustrate that 1 or 3 might be the optimal k-value. Thus, 3 clusters will be the best choice since k = 1 means a valueless clustering.
| k-value=2 | k-value=3 | k-value=4 | |
|---|---|---|---|
| For Record Data |
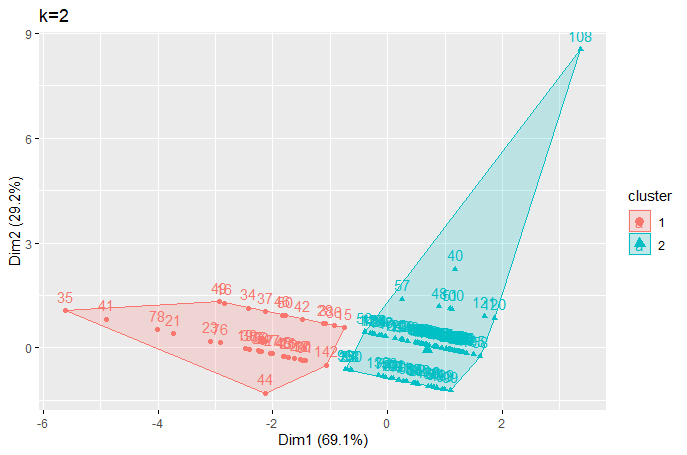
(Click to see a larger view.) |
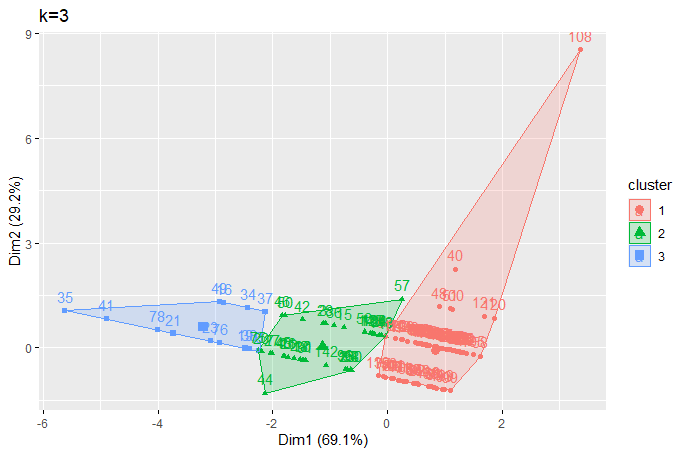
(Click to see a larger view.) |
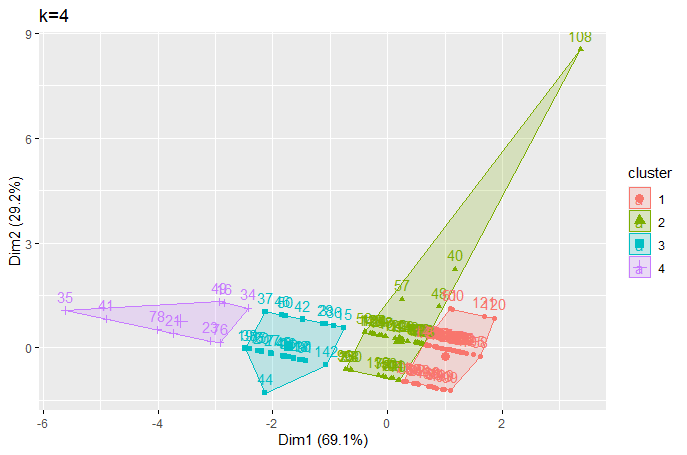
(Click to see a larger view.) |
| For Text Data |
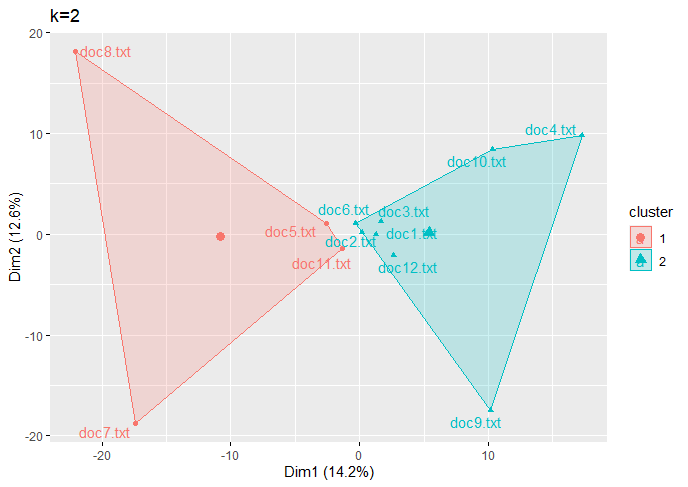
(Click to see a larger view.) |
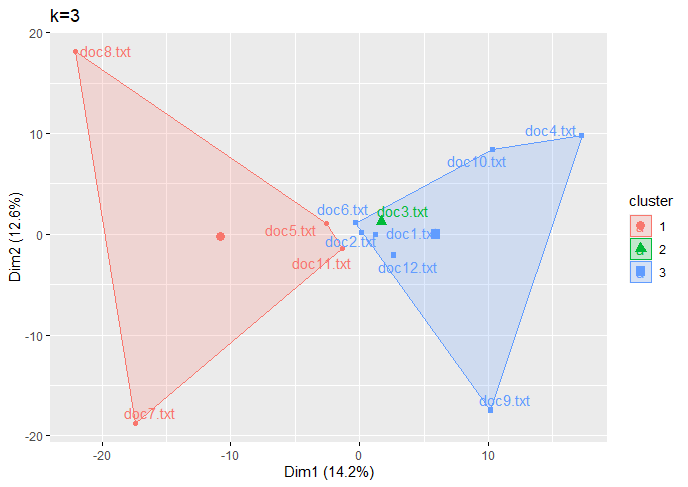
(Click to see a larger view.) |
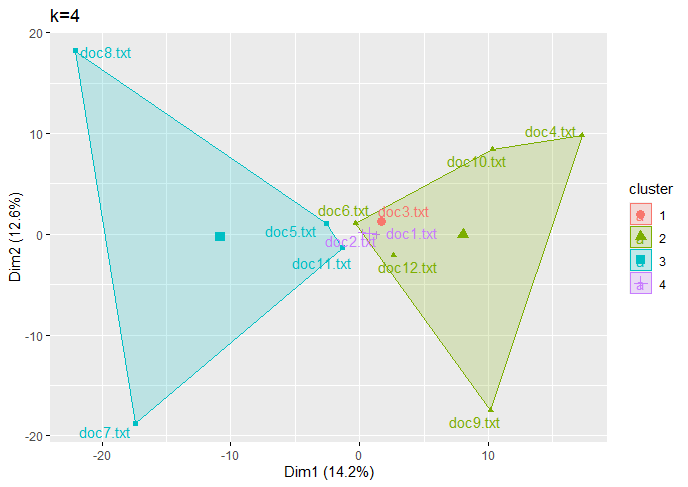
(Click to see a larger view.) |
It seems the optimal k-value is 2 for both record and text data.
| Manhattan Distance | Euclidean Distance | Canberra Distance | |
|---|---|---|---|
| For Record Data |
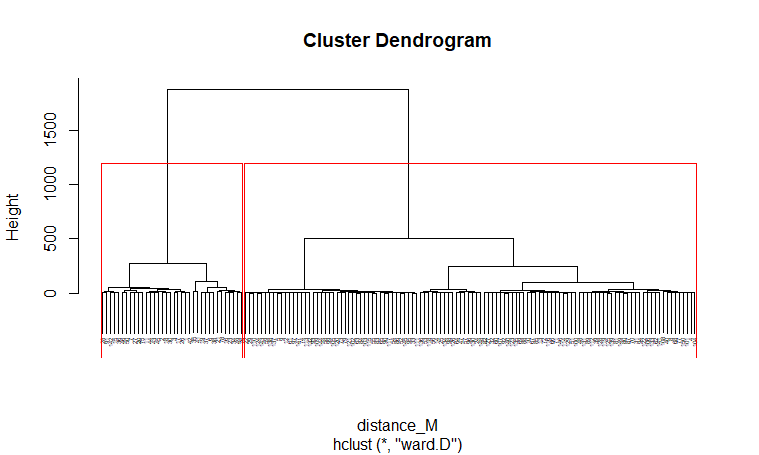
(Click to see a larger view.) |
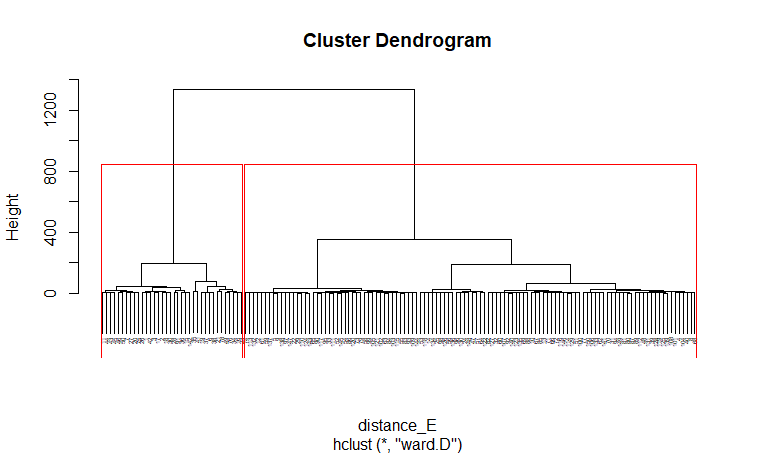
(Click to see a larger view.) |
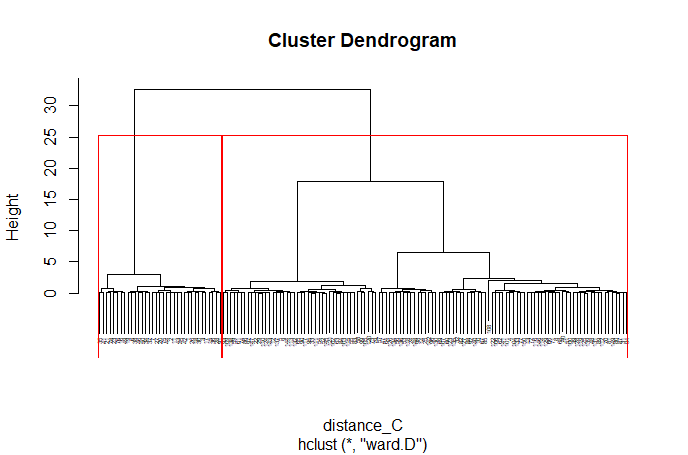
(Click to see a larger view.) |
| For Text Data |

(Click to see a larger view.) |
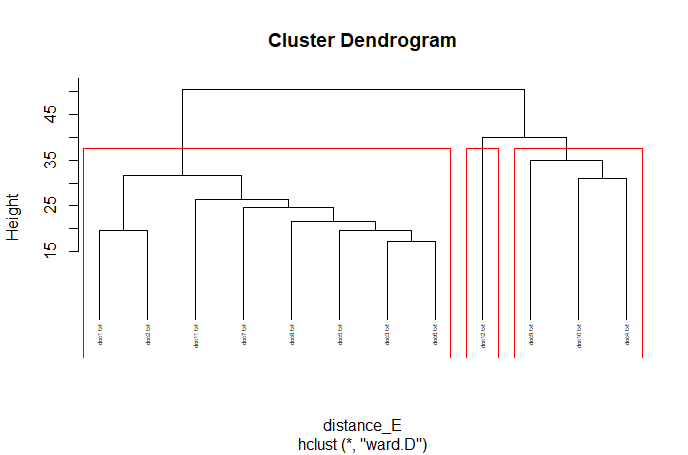
(Click to see a larger view.) |
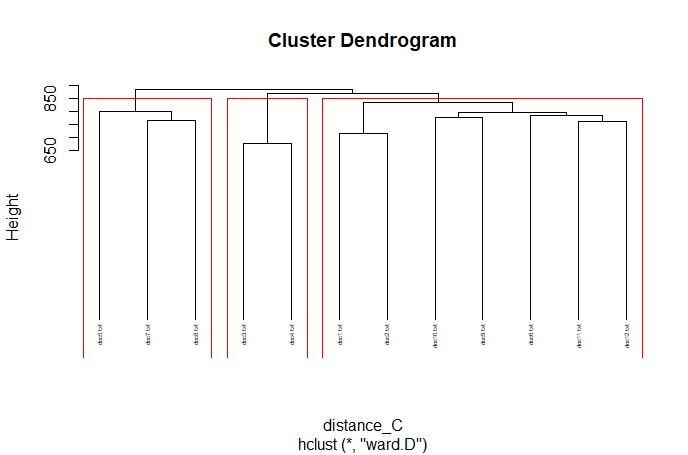
(Click to see a larger view.) |
For record data, Manhattan distance and Euclidean distance are much more similar than Canberra distance. And for text data, Manhattan distance and Canberra distance are more similar.
For record data, the optimal k-value is 2, and for text data, the optimal k-value is 3, which are the same as the previous results.
| For Record Data | For Text Data |
|---|---|
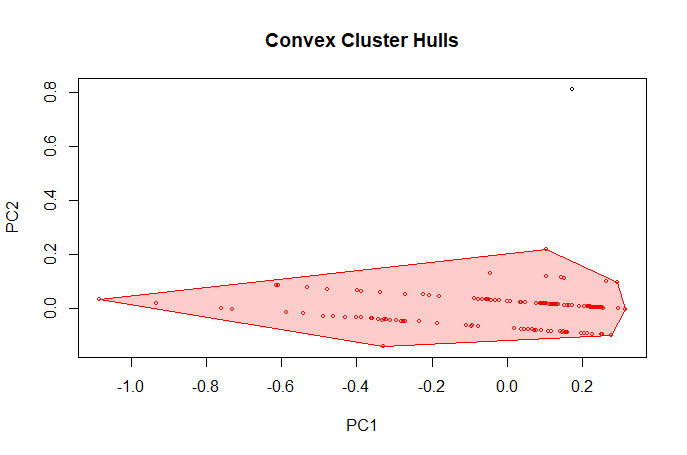
(Click to see a larger view.) |
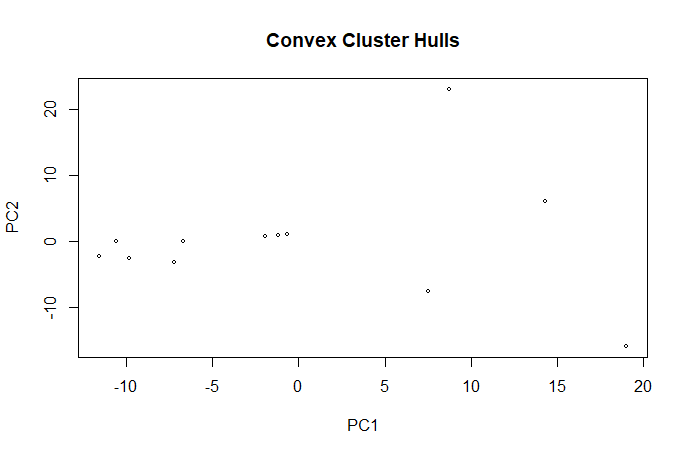
(Click to see a larger view.) |