
**Click here to get Record Data. Click here to get Text Data.
1) Decision Trees in R for Record Data: Click here to get R code.
| Before Cleaning | During Cleaning | After Cleaning |
|---|---|---|
(Click to see a larger view.) |
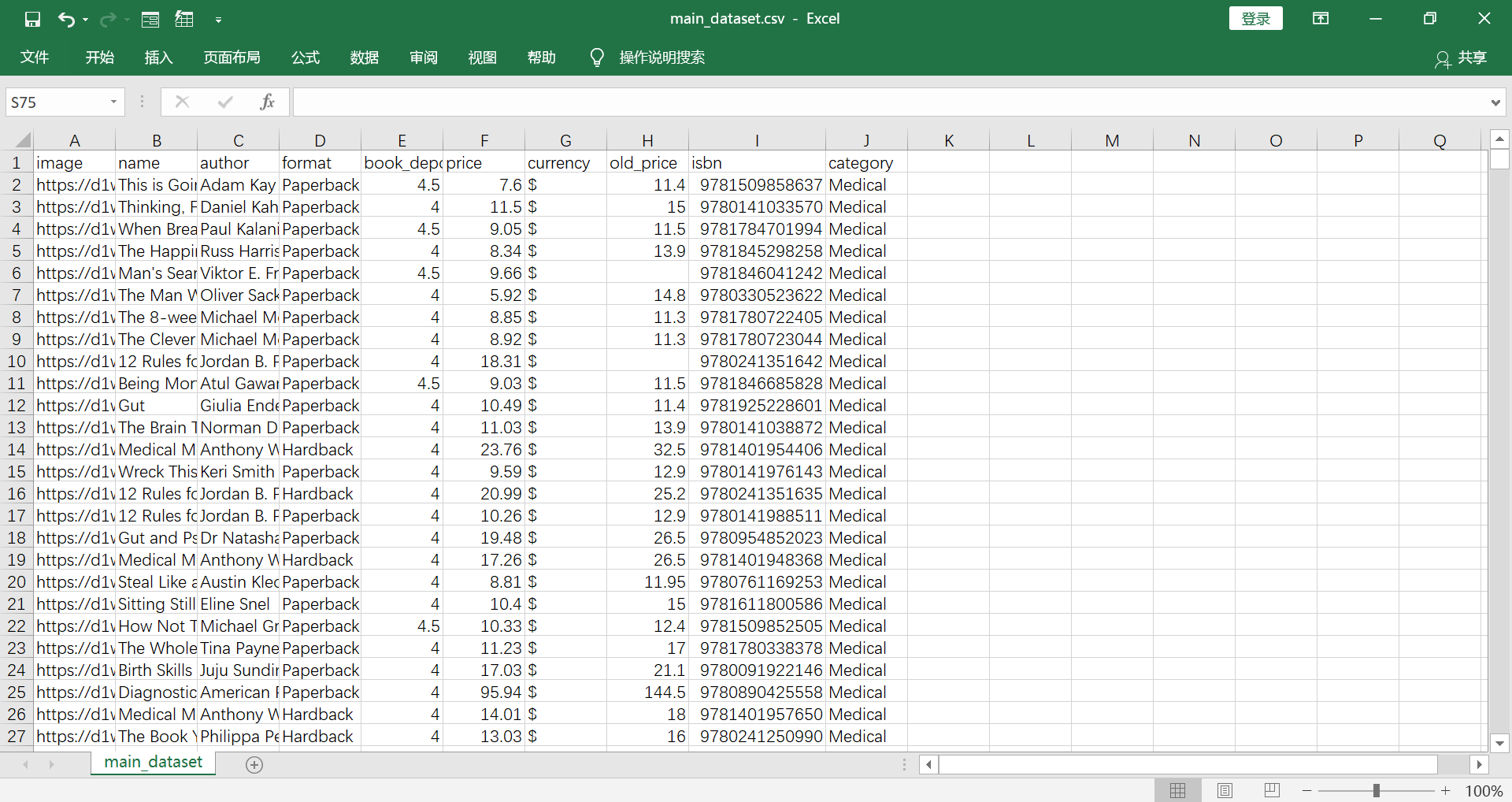
1) Remove the columns "image", "name", "author", "currency" and "isbn" which are useless data.
2) Remove the rows that have empty data. 3) Convert the type of "price" from factor to numeric. 4) For nominal data "category" and "format", use numbers to replace the data. One number represents one book category or format. 5) Choose some portions of rows proportionally to reduce the data size. |
(Click to see a larger view.) |
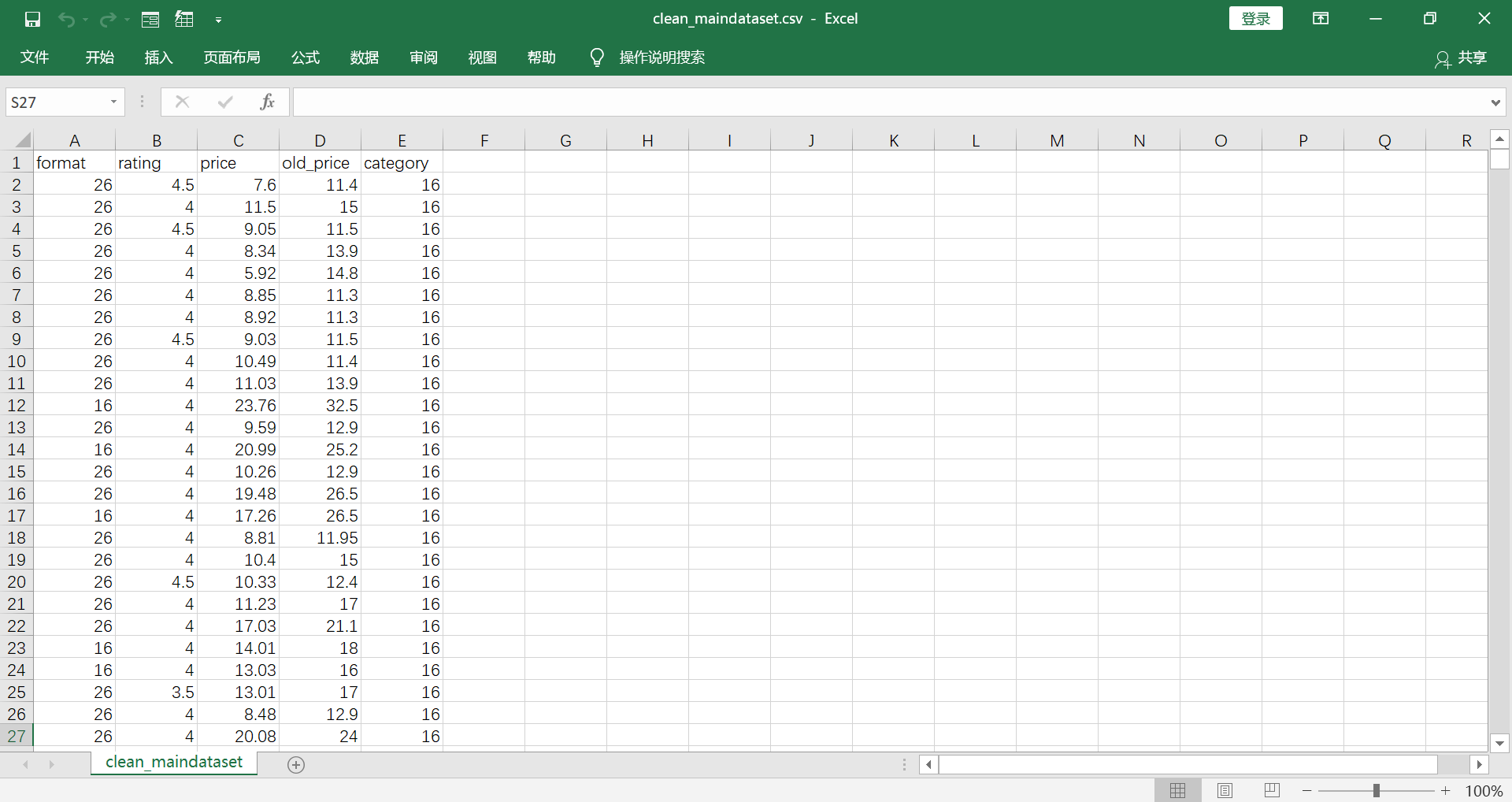
The labeled data is "rating" with 10 classes, 1 to 5 per 0.5 and 0.
| Bar Chart | Correlation Matrix |
|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
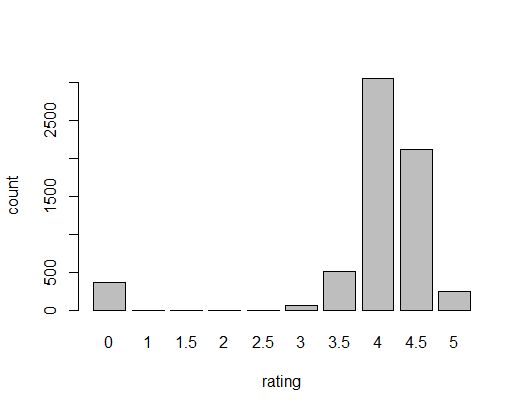
The bar chart shows that the rating of most books are 4 and 4.5 (4 is more). Few books have a rating of 1 to 3.
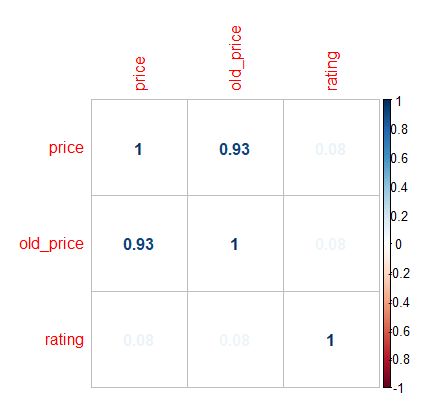
The correlation matrix shows that there is a strong correlation between price and old_price.
After splitting the data into train and test sets, the model called Decision Tree was created. Decision Tree is a supervised learning method used for classification and regression. In a decision tree, each internal node represents a test on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label. The paths from root to leaf represent classification rules. (From Wikipedia)
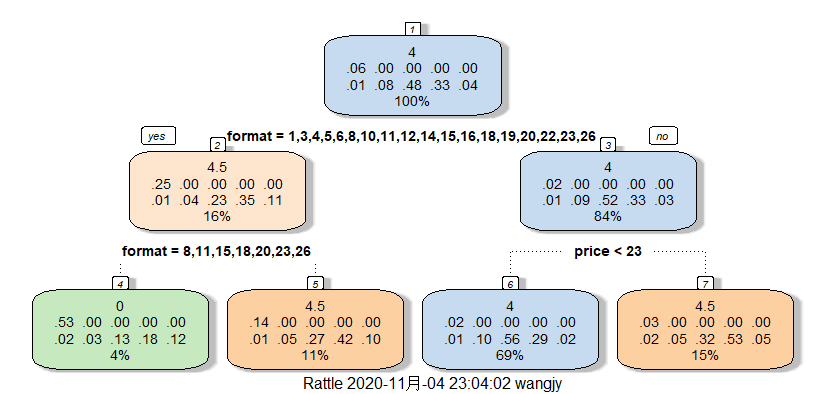
Choose "format" as the root:
| Decision Tree | Confusion Matrix |
|---|---|
(Click to see a larger view.) |

(Click to see a larger view.) |
From the decision tree, the data was split into four sets: if the books are in format of paperback, hardback and novelty, they gain a rating of 4.5, which is 11% of the data. If not, the books gain a rating of 0, which is 4% of the data. On the other hand, if the price of the books is greater than 23 dollars, the books gain a rating of 4.5, which is 15% of the data. If not, the books gain a rating of 4, which is 69% of the data.
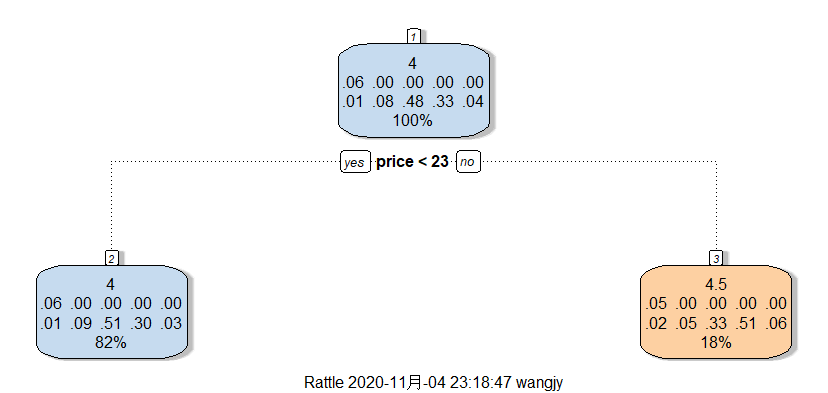
Choose "price" as the root:
| Decision Tree | Confusion Matrix |
|---|---|
(Click to see a larger view.) |

(Click to see a larger view.) |
From the decision tree, the data was split into two sets: if the price of the books is less than 23 dollars, the books gain a rating of 4, which is 82% of the data. By contrast, if the price of the books is greater than 23 dollars, the books gain a rating of 4.5, which is 18% of the data.
From the confusion matrix, the overall accuracy of the second tree is lower than that of the first tree.
| Importance Table |
|---|

(Click to see a larger view.) |
Random Forest was used to find the top significant variable in the decision of rating. Given that higher MeanDecreaseAccuracy is, more important the corresponding variable is, the most important variable is format.
2) Decision Trees and Random Forest in Python for Text Data: Click here to get Python code.
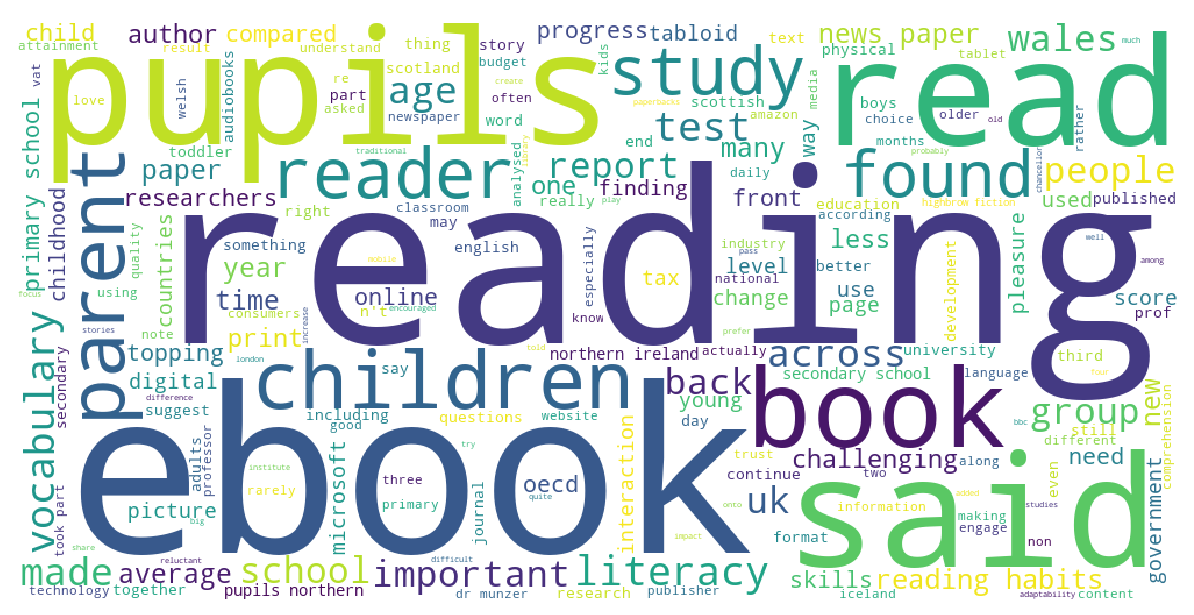
| Word Occurrence | Wordcloud |
|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
From the wordcloud, BBC news related to reading usually include topics about ebook, pupils, children, study, parent, vocabulary and so on.
| CountVectorize without binary |
CountVectorize with binary |
TfidfVectorize without stem |
TfidfVectorize with stem |
|
|---|---|---|---|---|
| Decision Tree |
(Click to see a larger view.) |
(Click to see a larger view.) |
(Click to see a larger view.) |
(Click to see a larger view.) |
| Confusion Matrix |

(Click to see a larger view.) The accuracy is 33.33%. |
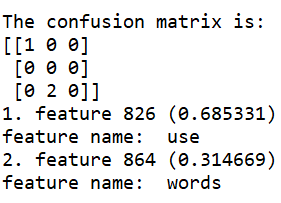
(Click to see a larger view.) The accuracy is 33.33%. |

(Click to see a larger view.) The accuracy is 0. |

(Click to see a larger view.) The accuracy is 25%. |
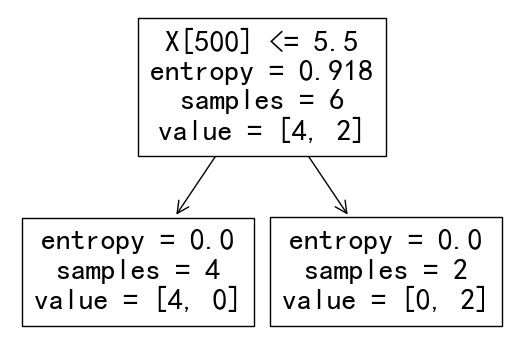
From the decision tree built by CountVectorize without binary, the data was split into two sets: word occurrance of "pupil"<=5.5 and word occurrance of "pupil">5.5.
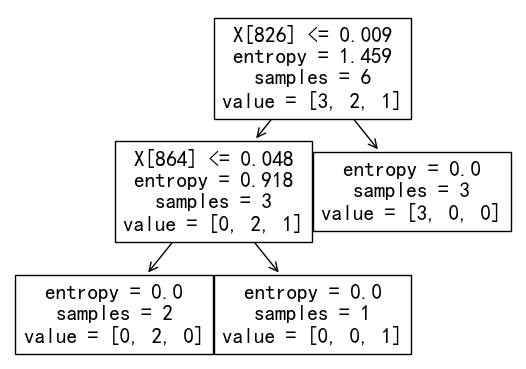
From the decision tree built by CountVectorize with binary, the data was split into three sets: word occurrance of "use">0.009, word occurrance of "use"<=0.009 & word occurrance of "words"<=0.048 and word occurrance of "use"<=0.009 & word occurrance of "words">0.048.
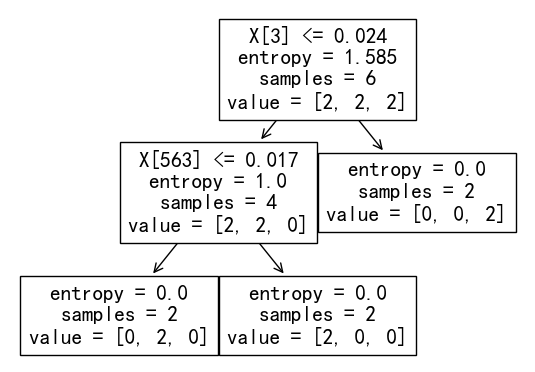
From the decision tree built by TfidfVectorize without stem, the data was split into three sets: tf-idf probability of "accord">0.024, tf-idf probability of "accord"<=0.024 & tf-idf probability of "say"<=0.017 and tf-idf probability of "accord"<=0.024 & tf-idf probability of "say">0.017.
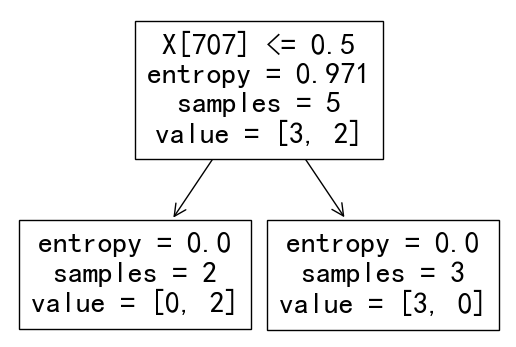
From the decision tree built by TfidfVectorize with stem, the data was split into two sets: tf-idf probability of "way"<=0.5 and tf-idf probability of "way">0.5.
From the confusion matrix, the decision trees built by CountVectorize have higher accuracy to predict the label.
| Feature Importance | Decision Surface |
|---|---|
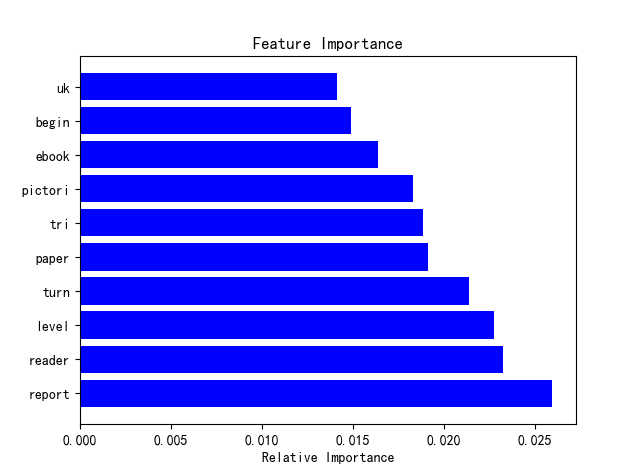
(Click to see a larger view.) |
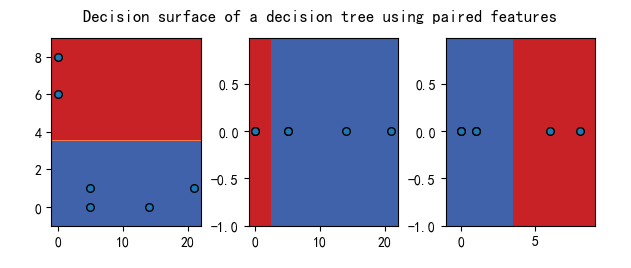
(Click to see a larger view.) |
From the feature importance plot, the most important words are "report", "reader" and "level".
Three words "ebook", "paper", "pupil" were picked and visualized how they get predicted by pairing two of them up without order, which is the decision surface plot.
Random Forest is an ensemble learning method for classification and regression that operates by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean/average prediction (regression) of the individual trees. Random Forest corrects for Decision Tree's habit of overfitting to their training set.
(From Wikipedia)
| Random Forest |
|---|
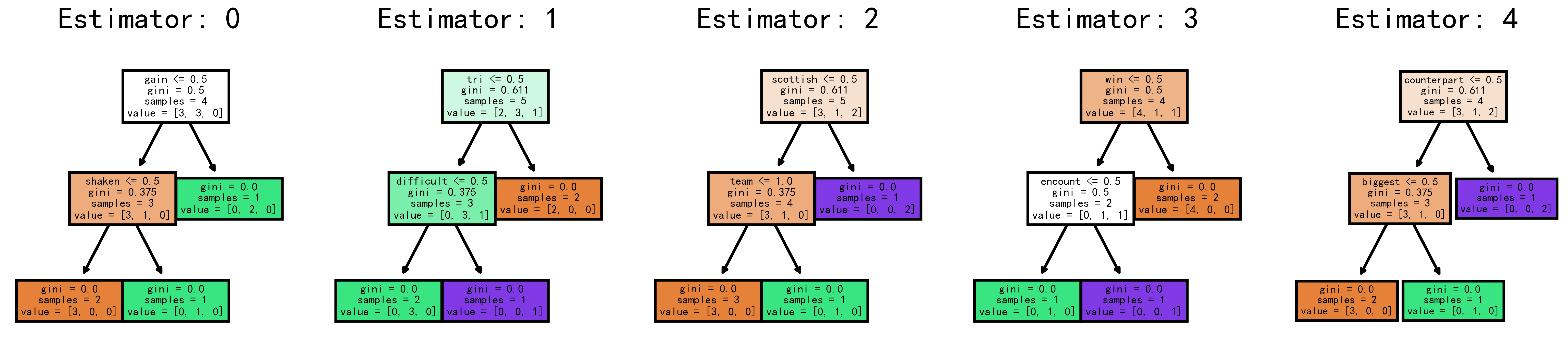
(Click to see a larger view.) |
When the number of estimator is 0, the data was split into three sets: word occurrance of "gain">0.5, word occurrance of "gain"<=0.5 & word occurrance of "shaken"<=0.5 and word occurrance of "gain"<=0.5 & word occurrance of "shaken">0.5.
When the number of estimator is 1, the data was split into three sets: word occurrance of "tri">0.5, word occurrance of "tri"<=0.5 & word occurrance of "difficult"<=0.5 and word occurrance of "tri"<=0.5 & word occurrance of "difficult">0.5.
When the number of estimator is 2, the data was split into three sets: word occurrance of "scottish">0.5, word occurrance of "scottish"<=0.5 & word occurrance of "team"<=1 and word occurrance of "scottish"<=0.5 & word occurrance of "team">1.
When the number of estimator is 3, the data was split into three sets: word occurrance of "win">0.5, word occurrance of "win"<=0.5 & word occurrance of "encount"<=0.5 and word occurrance of "win"<=0.5 & word occurrance of "encount">0.5.
When the number of estimator is 4, the data was split into three sets: word occurrance of "counterpart">0.5, word occurrance of "counterpart"<=0.5 & word occurrance of "biggest"<=0.5 and word occurrance of "counterpart"<=0.5 & word occurrance of "biggest">0.5.
3) Conclusion
In the first part, from the decision trees of record data, book format is the most important feature in the decision of rating. If the books are in format of paperback, hardback and novelty, they are more likely to gain higher ratings. This indicates that paper books are more popular. In addition, more expensive books gain higher ratings. This is an interesting finding! Most people prefer attractive book covers and wonderful stories to lower prices.
In the second part, from the feature importance plot of text data, the most important words are "report", "reader" and "level". The relative importance of "paper" is higher than that of "ebook". This indicates that paper books are more popular than ebooks, which is the same as the result of decision trees of record data.