
**Click here to get Record Data for R. Click here to get Record Data for Python. Click here to get Text Data.
1) Naive Bayes in R for Record Data: Click here to get R code.
| Book Rating by Format | Book Rating by Category |
|---|---|

(Click to see a larger view.) |
(Click to see a larger view.) |
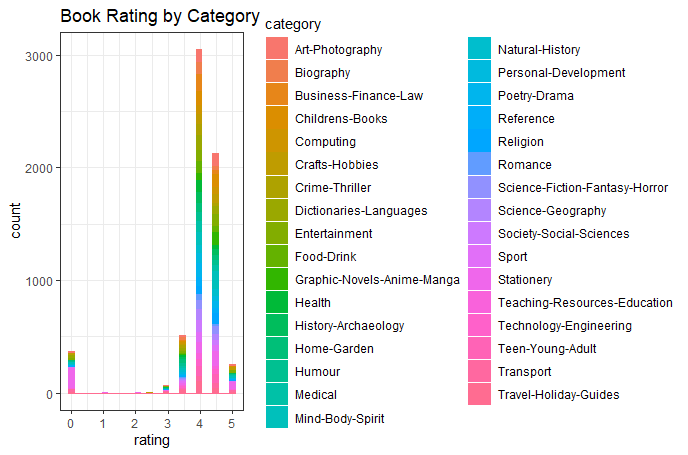
From the left histogram, the main book formats are hardback and paperback.
| Part of the Result of Naive Bayes | |
|---|---|
(Click to see a larger view.) |
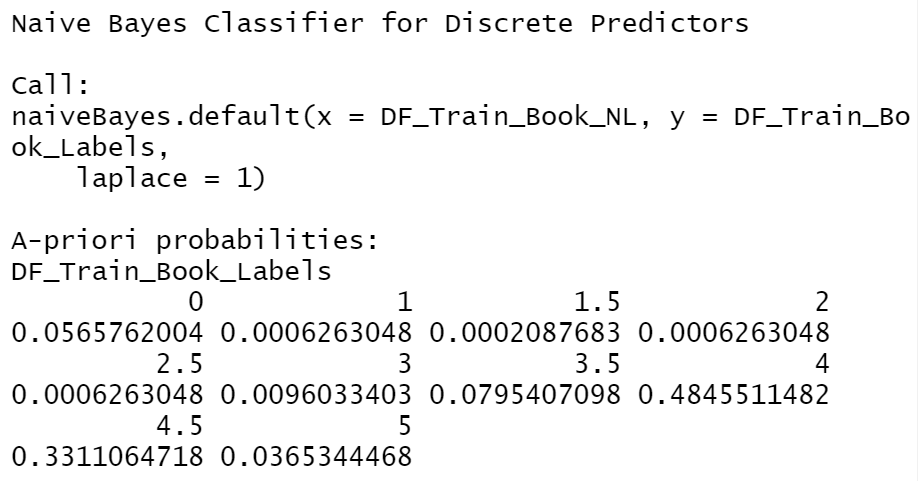
The rating 4 and 4.5 have the highest a priori probability. |
(Click to see a larger view.) |
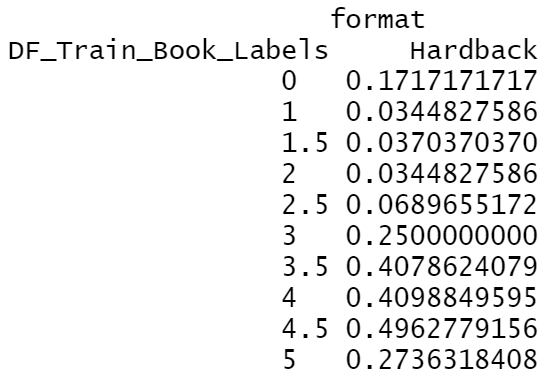
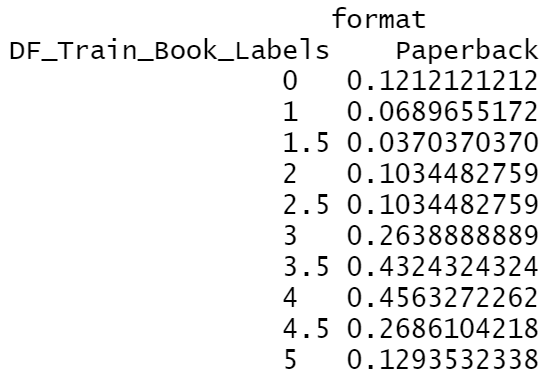
The format "Hardback" and "Paperback" have the highest probability of ratings, especially for the rating 3 to 4.5 groups. |
(Click to see a larger view.) |
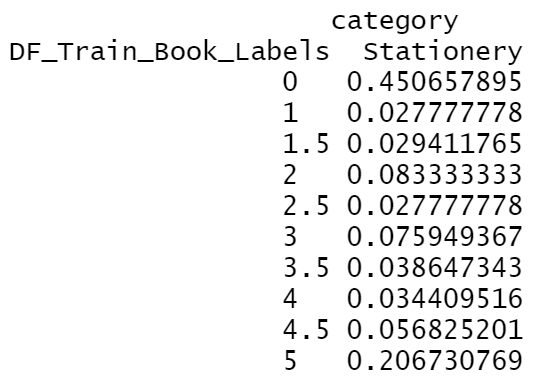
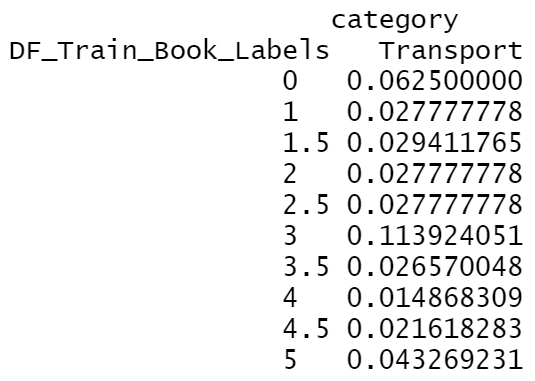
The category "Stationery" and "Transport" have the highest probability of ratings. |
(Click to see a larger view.) |
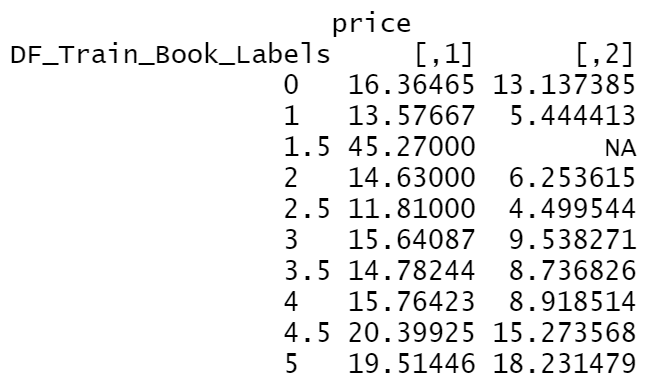
The mean price for the rating 1.5 group is significantly larger than any other groups. The variances for the rating 0, 4.5 and 5 book price are larger compared to the other variances for price for the other ratings. The variable "price" appears not to have such effect on "rating". |
| Confusion Matrix |
|---|
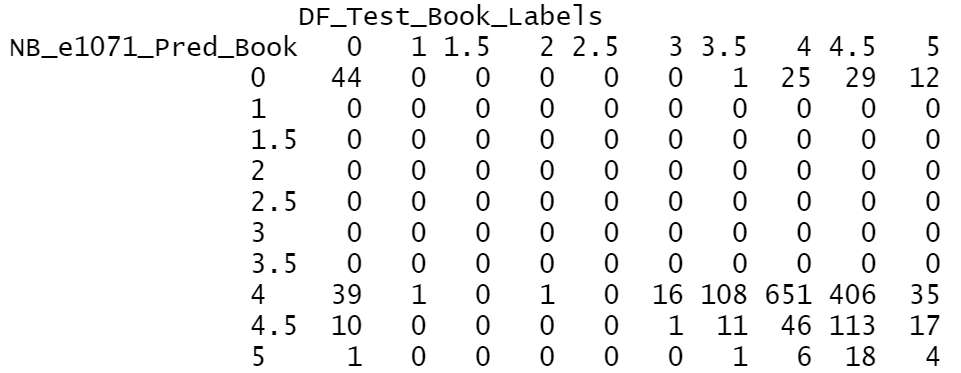
(Click to see a larger view.) |
The larger the number is on the diagonal, the better the model is. The accuracy of this model is 50.88%, not that good.
| Actual Label | Predicted Label |
|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
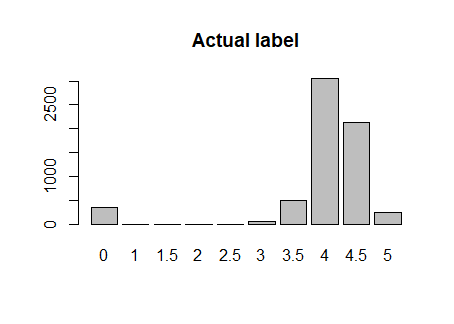
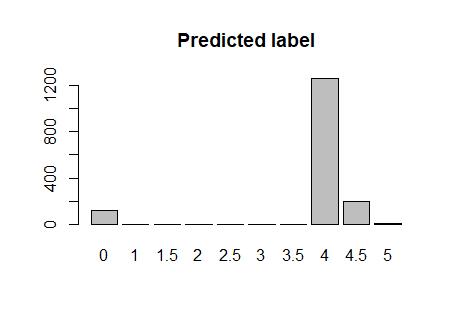
From the bar charts, plenty of "rating 4.5" and most of "rating 3.5" are not predicted correctly.
2) Naive Bayes in R for Text Data: Click here to get R code.
| Wordcloud for E-books | Wordcloud for Paper Books |
|---|---|

(Click to see a larger view.) |
(Click to see a larger view.) |
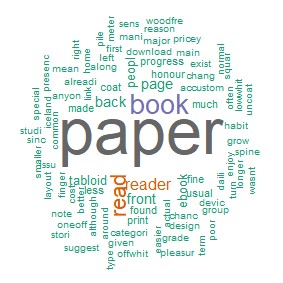
The main topics of BBC news related to e-books are children, parent and story. The main topic of BBC news related to paper books is reader.
| Word Frequency for E-books | Word Frequency for Paper Books |
|---|---|
(Click to see a larger view.) |
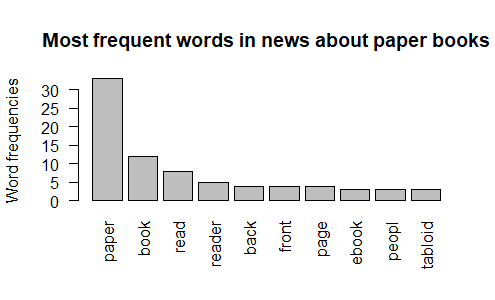
(Click to see a larger view.) |
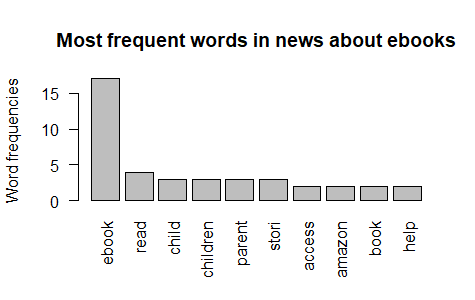
The most frequent words in BBC news about e-books and paper books are the same as the results of wordclouds.
| Part of the Result of Naive Bayes | |
|---|---|

(Click to see a larger view.) |
The a priori probability of paper books is higher than that of e-books. |


(Click to see a larger view.) |
The word "ebook" occurs in BBC news about e-books 4 times averagely and in that about paper books once per news. The word "paper" occurs in BBC news about paper books 6.33 times averagely and never in that about e-books. |
| Confusion Matrix | |
|---|---|

(Click to see a larger view.) |
The accuracy of this model is 66.67%. Three "ebooks" are predicted and two are actually correct. |
| Actual Label | Predicted Label |
|---|---|
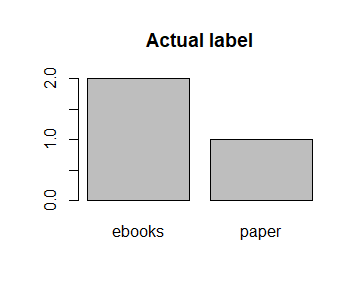
(Click to see a larger view.) |
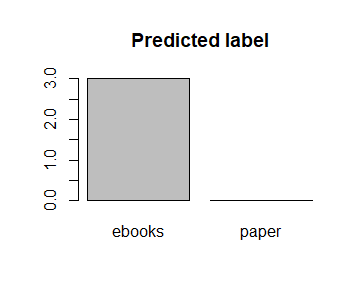
(Click to see a larger view.) |
From the bar charts, the same result can be gained as the confusion matrix. Three "ebooks" are predicted but there are actually two. One "paper" is wrongly predicted.
3) Naive Bayes in Python for Record Data: Click here to get Python code.
| Confusion Matrix | |
|---|---|
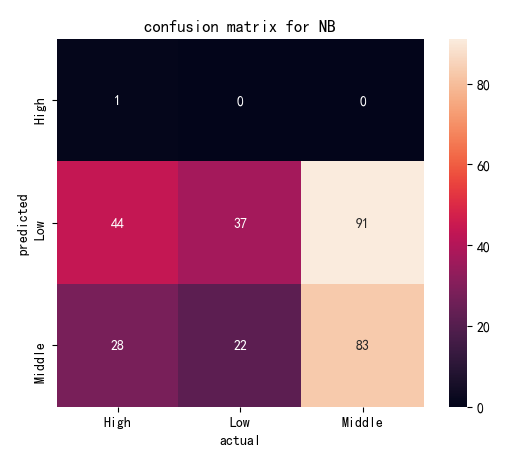
(Click to see a larger view.) |
There are quite a lot of data staying outside the diagonal of the confusion matrix, so this prediction has low accuracy. Actually, the accuracy of this model is only 39.54%. It can also be observed from the screenshot below. |
| Accuracy Score | |
|---|---|
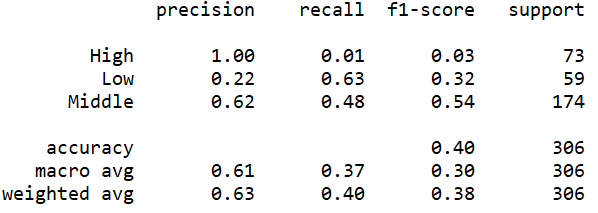
(Click to see a larger view.) |
Besides accuracy, three measures, precision, recall and f1-score can be observed from this screenshot. F1-score is the synthesis of precision and recall, which is more reliable. The f1-score of "Middle" is the highest, which indicates that more data in "Middle" rating are correctly predicted. |
| Actual Label | Predicted Label |
|---|---|
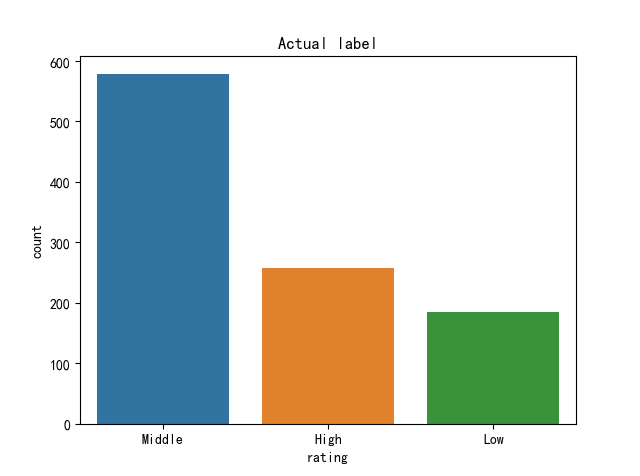
(Click to see a larger view.) |
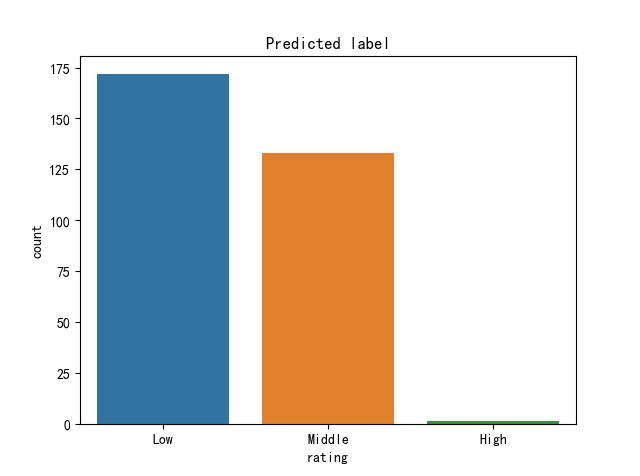
(Click to see a larger view.) |
Most data are predicted as "Middle" and "Low" and seldom as "High", while in actual dataset, "Low" label has the minimum data. This model gives more predictions on "Low" than the dataset actually has. In contrast, nearly all of the "High" labeled data are wrongly predicted.
4) Naive Bayes in Python for Text Data: Click here to get Python code.
To compare different results, vectorized data was created by "CountVectorizer" and "TfidfVectorize" respectively. The data created by "TfidfVectorizer" is after normalization.
|
Vectorized Words by CountVectorize |

(Click to see a larger view.) |
|
Vectorized Words by TfidfVectorize |
(Click to see a larger view.) |
| CountVectorize without binary |
CountVectorize with binary |
TfidfVectorize without stem |
TfidfVectorize with stem |
|---|---|---|---|

(Click to see a larger view.) |

(Click to see a larger view.) |

(Click to see a larger view.) |

(Click to see a larger view.) |
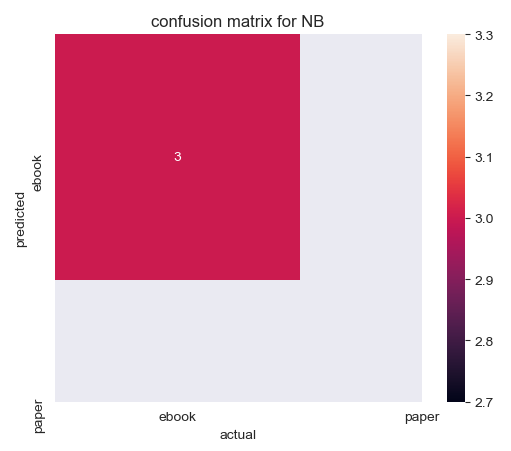
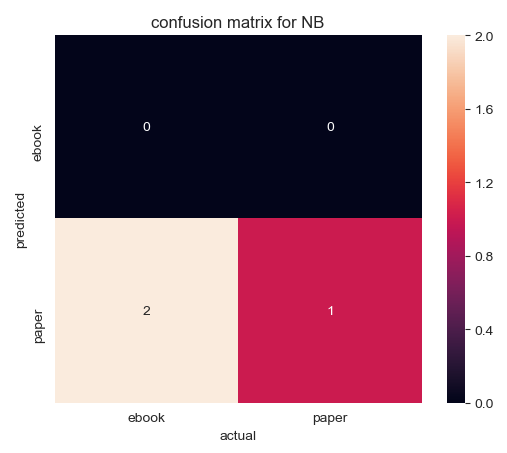
From the model built by CountVectorize without binary, three "ebooks" are predicted and they are all correct. The model built by CountVectorize with binary predicts three "paper", two of them are correct and one is wrong.
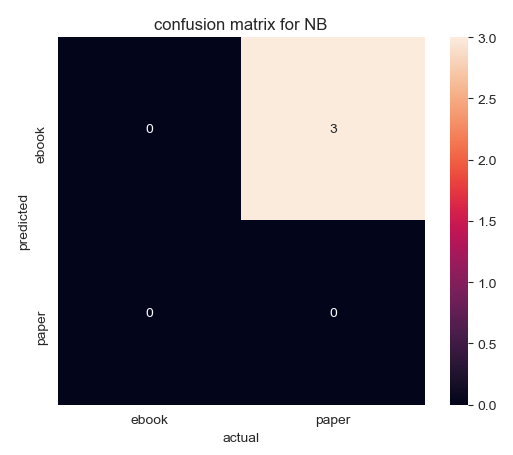
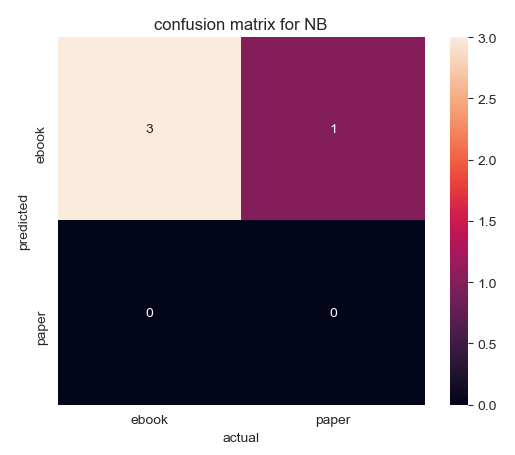
The model built by TfidfVectorize without stem predicts three "ebooks", while their actual labels are all "paper". From the model built by TfidfVectorize with stem, four "ebooks" are predicted, but there are actually three. One "paper" is wrongly predicted.
| CountVectorize without binary |
CountVectorize with binary |
TfidfVectorize without stem |
TfidfVectorize with stem |
|---|---|---|---|
(Click to see a larger view.) |
(Click to see a larger view.) |
(Click to see a larger view.) |
(Click to see a larger view.) |
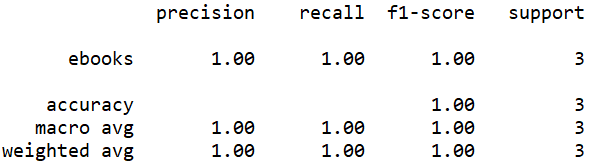
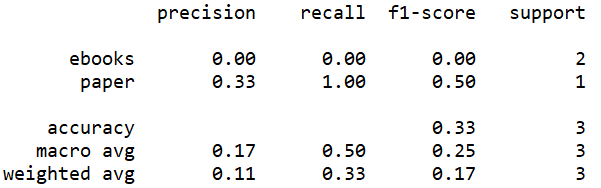
By checking the elements on the diagonal, the accuracy of four models can be calculated. The accuracy of the model built by CountVectorize without binary is 100%, which is the most accurate model. The accuracy of the model built by CountVectorize with binary is 33.33%.
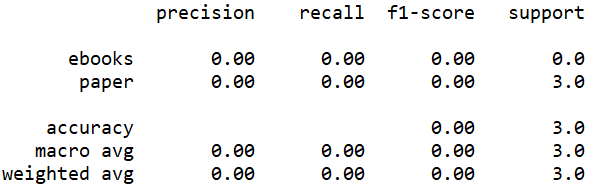
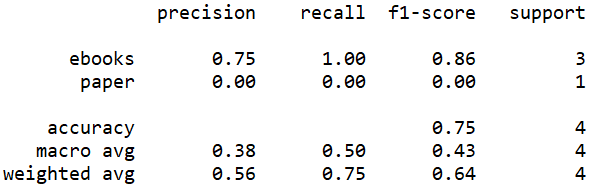
The accuracy of the model built by TfidfVectorize without stem is 0, which is the least accurate model. The accuracy of the model built by TfidfVectorize with stem is 75%.
| CountVectorize without binary |
(Click to see a larger view.) |
| CountVectorize with binary |
(Click to see a larger view.) |
| TfidfVectorize without stem |
(Click to see a larger view.) |
| TfidfVectorize with stem |
(Click to see a larger view.) |
The accuracy can be observed from these screenshots above. In addition, three measures, precision, recall and f1-score can also be observed. F1-score is the most reliable one. The f1-score of the model built by CountVectorize without binary is the highest, at 1, which also indicates that this model is the most accurate one. The f1-score of the model built by TfidfVectorize without stem is the lowest, at 0, which also indicates that this model is the least accurate one.
5) Conclusion
In the first and third part, from Naive Bayes for record data, the rating 4 and 4.5 have the highest a priori probability, which means that most books in Amazon are of these two ratings. The format "Hardback" and "Paperback" have the highest probability of ratings, indicating the main book formats are hardback and paperback. As for book category, "Stationery" and "Transport" have the highest probability of ratings, which are two of the most popular categories. The mean price for the rating 1.5 group is significantly larger than any other groups, but "price" appears not to have significant effect on "rating".
In the second and fourth part, from Naive Bayes for text data, the main topics of BBC news related to e-books are children, parent and story, and the main topic of BBC news related to paper books is reader. As for The a priori probability of paper books is higher than that of e-books. In addition, the word "ebook" occurs in BBC news about e-books 4 times averagely and in that about paper books once per news. The word "paper" occurs in BBC news about paper books 6.33 times averagely and never in that about e-books.